
Why Advance Rate is Broken (But Don't Worry, We Fixed It)
Best Ball Data Bowl Submission: Why Advance Rate is Broken (But Don't Worry, We Fixed It)
Why Advance Rate is Broken (But Don't Worry, We Fixed it)
Participants:
Sackreligious
Hackr6849
https://spikeweek.com/
Advance rate is a very commonly cited metric used to measure how impactful a player was in helping (or hurting) teams advance to the playoffs. The current method of calculating advance rate is simply the number of advancing teams that contain a specific player divided by the total number of times that player was drafted. There is a substantial amount of noise that muddies the signal contained in advance rate the way it is currently calculated. Some of the biases that reduce the value of advance rate in its current form include but are not limited to:
*Combinations of players can occur at different rates due to things like stacking and ADPs that line up with certain draft slots
*Roster constructions can have uneven distributions of certain players; 0 RB teams may be more likely to have certain players than robust RB teams etc.
*Drafter skill matters. Above average drafters may be more likely to select certain players they have evaluated as "good picks" and less likely to select players they have evaluated as "bad picks". While they may be incorrect about their individual evaluation of a player with respect to the results of the specific season, they may have an overall advantage over the field leading to inflated advance rates of players they select more frequently. The inverse can be said about low skill drafters.
The goals of this project are to provide less noisy, more useful metrics for measuring past player performance, and perhaps better identifying player profiles we should be targetting in future best ball drafts. The four metrics we have developed are:
*Roster Agnostic Advance Rate (RAAR), a new more accurate method of determining the impact an individual player had on the ability of a team to advance to the playoffs. By swapping a specific player on to each team and recalculating the advance rate 1 team at a time by simulating the pod with 2022 results, we are able to remove many of the biases that currently plague advance rate. We choose the player we want to calculate RAAR for, and iterate through each draft_id, adding the player to one team at a time in each 12 team draft, and removing the player on the target roster that was selected with the pick closest to the ADP of the player we are swapping on to the team, provided those two players are the same position. We then recalculate the weekly score for this team, and test to see if the team would have advanced with the player that we are calculating RAAR for. We repeat this process for each team in the 12 team draft (no swap is required for the team that already has the target player on their roster). We then repeat this process for each draft_id in BBM3.
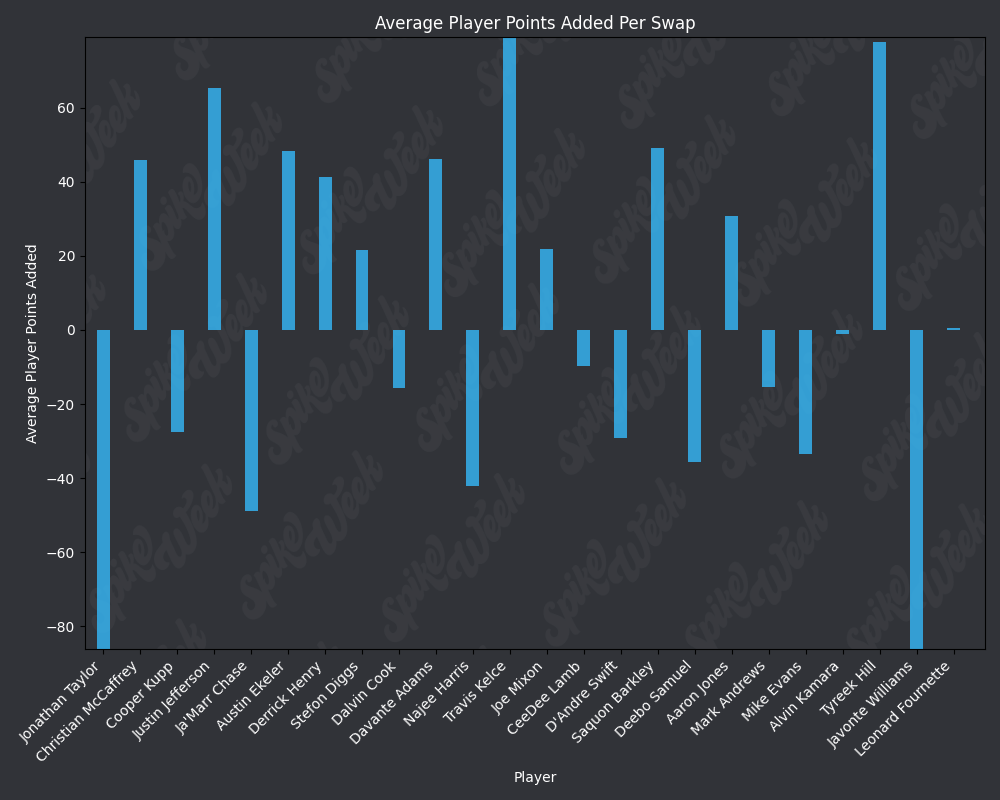
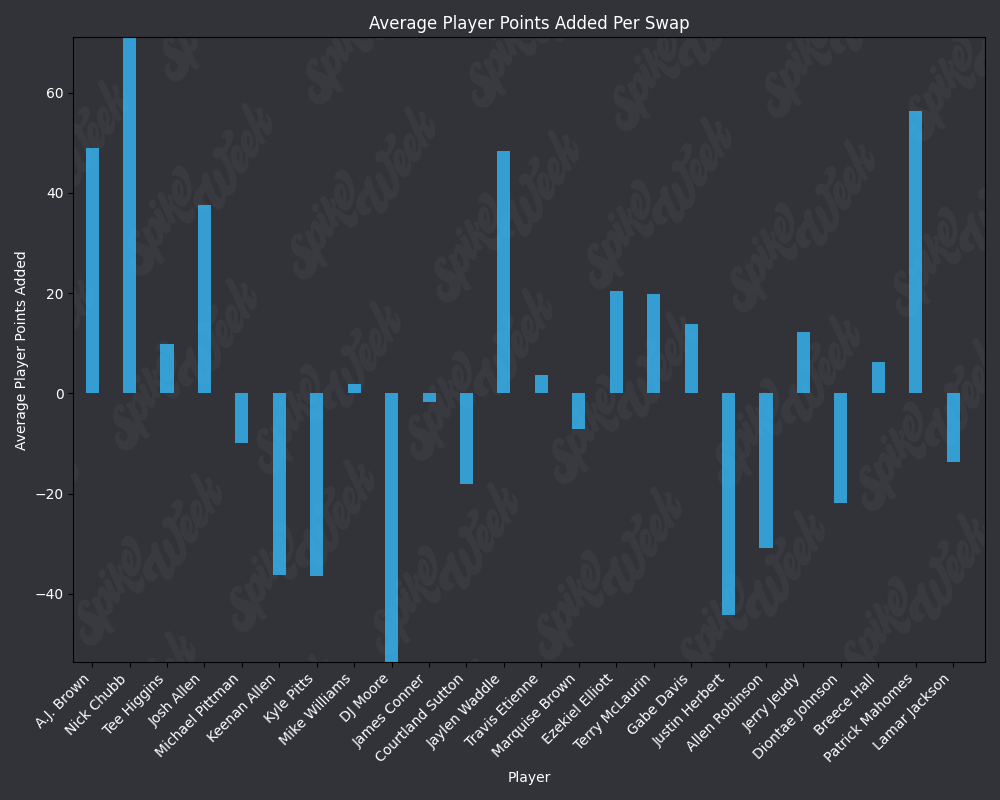
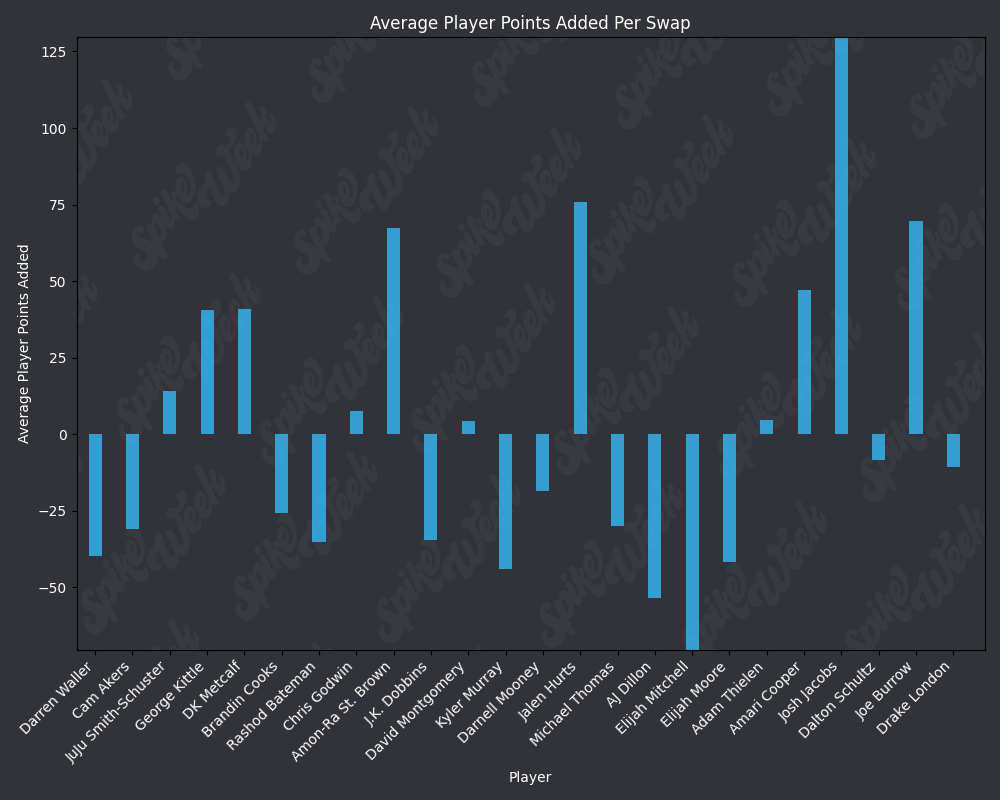
*Average Player Points Added (APPA), a new metric that follows a similar player swapping methodology to compare players that were being selected in a similar ADP range to help measure which picks were actually best at a given point in drafts.
*Player Points Contributed to Advancing Teams (PPCAT), a new metric that follows a similar player swapping methodology to compare the percentage of total roster points that a specific player contributed to advancing teams.
*Player Points Contributed to Teams (PPCT), the same methodology as PPCAT, but for all teams instead of specifically advancing teams.
First we create a table of weekly fantasy scores for each player for 2022.
import sqlite3
import pandas as pd
import nfl_data_py as nfl
# Scoring rules
def calculate_fantasy_points(row):
points = 0.0
points += row['receptions'] * 0.5
points += row['receiving_tds'] * 6.0
points += row['receiving_yards'] * 0.1
points += row['rushing_tds'] * 6.0
points += row['rushing_yards'] * 0.1
points += row['passing_yards'] * 0.04
points += row['passing_tds'] * 4.0
points += row['interceptions'] * -1.0
points += row['passing_2pt_conversions'] * 2.0
points += row['rushing_2pt_conversions'] * 2.0
points += row['receiving_2pt_conversions'] * 2.0
points += row['sack_fumbles_lost'] * -2.0
points += row['rushing_fumbles_lost'] * -2.0
points += row['receiving_fumbles_lost'] * -2.0
return points
# Specify the years and columns you are interested in
years = [2022]
columns = ['player_id', 'player_name', 'player_display_name', 'position', 'season', 'week', 'passing_yards', 'passing_tds', 'interceptions', 'sack_fumbles_lost', 'passing_2pt_conversions', 'rushing_yards', 'rushing_tds', 'rushing_fumbles_lost', 'rushing_2pt_conversions', 'receptions', 'receiving_yards', 'receiving_tds', 'receiving_fumbles_lost', 'receiving_2pt_conversions', 'special_teams_tds']
# Fetch the weekly data
weekly_data = nfl.import_weekly_data(years, columns)
# Calculate the fantasy points for each week and store in a new column
weekly_data['fantasy_points'] = weekly_data.apply(calculate_fantasy_points, axis=1)
# Transform the data to the required format
weekly_scores = weekly_data.pivot_table(index=['player_display_name', 'position'], columns='week', values='fantasy_points', fill_value=0)
# Convert the pivot table to a DataFrame and reset the index
weekly_scores_df = pd.DataFrame(weekly_scores.to_records())
# Connect to the SQLite database
conn = sqlite3.connect('bestball.db')
# Write the DataFrame to the SQLite database
weekly_scores_df.to_sql('FPTS_UD_2022', conn, if_exists='replace', index=False)
# Close the database connection
conn.close()We dump ADP data and player ID to JSON files
import requests
from datetime import datetime, timedelta
import json
f = open('rawAdpData.datajson', 'r')
adpData = json.loads(f.read())
f.close()
playerAdps = {}
playerIds = {}
vals = {}
for date in adpData:
data = adpData[date]
for val in data:
adp = val['adp']
dateVal = val['date']
playerName = val['playerpositiondraftgroup']['player']['playerName']
playerId = val['playerpositiondraftgroup']['playerDraftGroupId']
if playerName not in playerIds:
playerIds[playerName] = []
if playerId not in playerIds[playerName]:
playerIds[playerName].append(playerId)
if dateVal not in playerAdps:
playerAdps[dateVal] = {}
playerAdps[dateVal][playerId] = adp
f = open('playerAdpData.datajson', 'w')
f.write(json.dumps(playerAdps))
f.close()
f = open('playerIds.datajson', 'w')
f.write(json.dumps(playerIds))
f.close()Do precalculations and save to JSON files
import pandas as pd
import logging
import sqlite3
import json
from tqdm import tqdm
def calculate_weekly_score(team, week_number):
team_scores = df_scores[df_scores['normalized'].isin(team['normalized'])]
unmatched = set(team['normalized']) - set(team_scores['normalized'])
for player in unmatched:
logging.error(
f"Week {week_number}, Team {team['draft_entry_id'].values[0]}: Player {player} not found in 'UD_FPTS_2022' table")
positions = ['QB', 'RB', 'WR', 'TE']
score = 0.0
starting_lineup = {}
playersUsed = []
for pos in positions:
num_required = 2 if pos == 'RB' else 3 if pos == 'WR' else 1
players_pos = team_scores[team_scores['position'] == pos]
# Sort by scores for the given week, and avoid repeating players
sorted_players = players_pos.sort_values(by=f'{week_number}', ascending=False)
top_players = sorted_players.drop_duplicates(subset=['normalized']).head(num_required)
score += top_players[f'{week_number}'].sum()
#starting_lineup += [{'n' : top_players['player_display_name'], 's' : top_players[f'{week_number}']}]
playerNames = list(top_players['player_display_name'])
playerScores = list(top_players[f'{week_number}'])
starting_lineup[pos] = {}
for i in range(len(playerNames)):
starting_lineup[pos][playerNames[i]] = playerScores[i]
playersUsed.append(playerNames[i])
# Flex position
remaining_players = team_scores[(~team_scores['normalized'].isin(
[df_scores[df_scores['player_display_name'] == player]['normalized'].values[0] for player in
playersUsed])) & (team_scores['position'] != 'QB')]
# Provide a default value for max_score_player
max_score_player = None
if not remaining_players.empty:
max_score_player = remaining_players.loc[remaining_players[f'{week_number}'].idxmax()]
if max_score_player is not None:
score += max_score_player[f'{week_number}']
playerName = max_score_player['player_display_name']
playerScore = max_score_player[f'{week_number}']
playersUsed.append(playerName)
position = 'FLEX'
if position not in starting_lineup:
starting_lineup[position] = {}
starting_lineup[position][playerName] = playerScore
#top bench players
benchPlayers = {}
remaining_players = team_scores[(~team_scores['normalized'].isin(
[df_scores[df_scores['player_display_name'] == player]['normalized'].values[0] for player in
playersUsed]))]
for pos in positions:
num_required = 1
players_pos = remaining_players[remaining_players['position'] == pos]
# Sort by scores for the given week, and avoid repeating players
sorted_players = players_pos.sort_values(by=f'{week_number}', ascending=False)
top_players = sorted_players.drop_duplicates(subset=['normalized']).head(num_required)
playerNames = list(top_players['player_display_name'])
playerScores = list(top_players[f'{week_number}'])
positions = list(top_players['position'])
for i in range(len(playerNames)):
if positions[i] not in benchPlayers:
benchPlayers[positions[i]] = {}
benchPlayers[positions[i]][playerNames[i]] = playerScores[i]
return score, starting_lineup, benchPlayers
def calculate_team_score(team_id):
global playerAdps
team = df_teams[df_teams['draft_entry_id'] == team_id]
print(f'Team ID: {team_id}')
print(f"Player Names: {team['player_name'].values}\n")
players = list(team['player_name'])
pickRounds = list(team['team_pick_number'])
positions = list(team['position_name'])
adps = list(team['projection_adp'])
pickNums = list(team['overall_pick_number'])
draftDate = list(team['draft_time'])[0].split(' ')[0]
lineup = {}
for i in range(len(players)):
position = positions[i]
if position not in lineup:
lineup[position] = []
lineup[position].append({ 'name' : players[i], 'pos' : positions[i], 'pick' : pickNums[i] })
playerAdps[players[i]] = { 'p' : positions[i], 'a' : adps[i] }
# For each week, calculate the weekly score
total_score = 0.0
team_output = {}
for week in range(1, 15):
weekly_score, starting_lineup, benchLineup = calculate_weekly_score(team, week)
total_score += weekly_score
team_output[week] = { "l": starting_lineup, "s": weekly_score, "b" : benchLineup}
return team_id, total_score, team_output, lineup, draftDate
def batch_draft_ids(df_teams, batch_size):
unique_draft_ids = df_teams['draft_id'].unique()
for i in range(0, len(unique_draft_ids), batch_size):
yield unique_draft_ids[i:i + batch_size]
# create logger
logging.basicConfig(filename='error_logs.txt', level=logging.ERROR)
# load your data
df_scores = pd.read_sql('SELECT * FROM UD_FPTS_2022', con=sqlite3.connect('bestball.db'))
con = sqlite3.connect('bestball.db')
cur = con.cursor()
res = cur.execute('SELECT distinct draft_id FROM BBMIII WHERE tournament_round_number = 1')
draftIds = res.fetchall()
completedDrafts = []
try:
f = open('completedDrafts.txt', 'r')
lines = f.read().split('\n')
for line in lines:
completedDrafts.append(line)
f.close()
except:
pass
playerAdps = {}
try:
f = open('playerAdps.json', 'r')
playerAdps = json.loads(f.read())
f.close()
except:
pass
draftNum = 0
totalDrafts = len(draftIds)
dataFiles = ['precalc_data_new_1.json','precalc_data_new_2.json','precalc_data_new_3.json','precalc_data_new_4.json','precalc_data_new_5.json','precalc_data_new_6.json','precalc_data_new_7.json','precalc_data_new_8.json','precalc_data_new_9.json','precalc_data_new_10.json']
for draftId in draftIds:
draftId = draftId[0]
if draftId in completedDrafts:
draftNum += 1
continue
draftNum += 1
print('---------------------- PROCESSING DRAFT NUMBER %d OF %d------------------------' % (draftNum,totalDrafts))
df_teams = pd.read_sql('SELECT * FROM BBMIII WHERE tournament_round_number = 1 and draft_id = "%s"' % (draftId,), con=sqlite3.connect('bestball.db'))
# Normalize names by removing dots and spaces, and converting to lower case
df_scores['normalized'] = df_scores['player_display_name'].str.replace('[. ]', '').str.lower()
df_teams['normalized'] = df_teams['player_name'].str.replace('[. ]', '').str.lower()
batch_size = 100
final_results = {}
# Add tqdm() around the iterable
for batch in tqdm(batch_draft_ids(df_teams, batch_size), desc="Processing batches"):
batch_teams = df_teams[df_teams['draft_id'].isin(batch)]['draft_entry_id'].unique()
team_scores = {}
# Add tqdm() around the iterable
for team_id in tqdm(batch_teams, desc="Processing teams", leave=False):
team_id, team_score, team_output, lineup, draftDate = calculate_team_score(team_id)
draft_id = df_teams[df_teams['draft_entry_id'] == team_id]['draft_id'].values[0]
if draft_id not in team_scores:
team_scores[draft_id] = [(team_id, team_score, team_output, lineup, draftDate)]
else:
team_scores[draft_id].append((team_id, team_score, team_output, lineup, draftDate))
for draft_id, scores in team_scores.items():
sorted_scores = sorted(scores, key=lambda x: x[1], reverse=True)
final_results[draft_id] = {}
for i, (team_id, score, team_output, lineup, draftDate) in enumerate(sorted_scores, 1):
final_results[draft_id][team_id] = {"rank": i, "total_score": score, "team_output": team_output, "lineup" : lineup, "date" : draftDate}
if i == 1:
final_results['first'] = score
elif i == 2:
final_results['second'] = score
elif i == 3:
final_results['third'] = score
f = open('precalc_data_new_%d.json' % ((draftNum % 10) + 1), 'a')
f.write('%s\n' % (json.dumps(final_results),))
f.close()
f = open('completedDrafts.txt', 'a')
f.write('%s\n' % (draftId,))
f.close()
f = open('playerAdps.json', 'w')
f.write(json.dumps(playerAdps))
f.close()
#break
'''
# Save precalculation data and thresholds to JSON
with open(r'precalc_data.json', 'w') as outfile:
json.dump(final_results, outfile
'''Swap every player to every roster, one roster at a time, with a player of the same position taken near their ADP, then simulate the pod to calculate roster agnostic advance rate. Also calculate the average points a player added over replacement player's drafted within a range of their ADP, as well as PPCAT and PPCT.
import json
import pandas as pd
import sqlite3
import copy
def get_scores_for_player(player):
nameExceptions = {
'DJ Moore': 'D.J. Moore',
'AJ Dillon': 'A.J. Dillon',
'DJ Chark': 'D.J. Chark',
'KJ Hamler': 'K.J. Hamler'
}
# Fetch scores from the 'UD_FPTS_2022' dataframe for a given player
if player not in player_scores:
playerName = player
if player in nameExceptions:
playerName = nameExceptions[player]
scores_df = UD_FPTS_2022_df[UD_FPTS_2022_df['player_display_name'] == playerName]
player_scores[player] = {}
if len(scores_df.index) == 0:
return
for i in range(1, 15):
player_scores[player][i] = list(scores_df[str(i)])[0]
return player_scores[player]
def swap_player(team_data, player_to_swap, test_player, test_player_scores_dict, position):
# Make a deep copy of the team data so we don't modify the original data
new_team_data = copy.deepcopy(team_data)
# For each week in the team output
new_team_data['total_score'] = 0
for week_num in new_team_data['team_output']:
week_data = new_team_data['team_output'][week_num]
# First remove the player from the starting lineup if they were not in the starting lineup
# if player_to_swap in week_data['l'][position]:
# week_data['l'][player_to_swap] = test_player_scores_dict.get(week_data['week_number'], 0)
remove_player_from_lineup(week_data, player_to_swap, position)
if not test_player_scores_dict or int(week_num) not in test_player_scores_dict:
new_team_data['total_score'] += week_data['s']
continue
add_player_to_lineup(week_data, test_player, test_player_scores_dict[int(week_num)], position)
# If the player to swap is on the bench, replace his score with the test player's score
# elif player_to_swap in week_data['bench']:
# week_data['bench'][player_to_swap] = test_player_scores_dict.get(week_data['week_number'], 0)
new_team_data['total_score'] += week_data['s']
return new_team_data
'''
Remove a player from the lineup. If they are not in the lineup, nothing needs to happen
'''
def remove_player_from_lineup(lineup_data, player_to_remove, position):
if player_to_remove in lineup_data['l'][position]:
lineup_data['s'] = lineup_data['s'] - lineup_data['l'][position][player_to_remove]
lineup_data['l'][position].pop(player_to_remove, None)
if position in lineup_data['b']:
for player_to_add in lineup_data['b'][position]:
lineup_data['s'] += lineup_data['b'][position][player_to_add]
lineup_data['l'][position][player_to_add] = lineup_data['b'][position][player_to_add]
break
else:
player_to_add = None
high_score = 0
for pos in lineup_data['b']:
if pos == 'QB':
continue
for player_name in lineup_data['b'][pos]:
score = lineup_data['b'][pos][player_name]
if score > high_score:
player_to_add = player_name
high_score = score
break
if player_to_add:
lineup_data['s'] += high_score
lineup_data['l'][position][player_to_add] = high_score
elif player_to_remove in lineup_data['l']['FLEX']:
lineup_data['s'] = lineup_data['s'] - lineup_data['l']['FLEX'][player_to_remove]
lineup_data['l']['FLEX'].pop(player_to_remove, None)
player_to_add = None
high_score = 0
for position in lineup_data['b']:
if position == 'QB':
continue
for player_name in lineup_data['b'][position]:
score = lineup_data['b'][position][player_name]
if score > high_score:
player_to_add = player_name
high_score = score
break
if player_to_add:
lineup_data['s'] += high_score
lineup_data['l']['FLEX'][player_to_add] = high_score
def add_player_to_lineup(lineup_data, player_to_add, score, position):
if position == 'QB':
qbScore = 0
for playerName in lineup_data['l']['QB']:
qbScore = lineup_data['l']['QB'][playerName]
break
if qbScore < score:
lineup_data['s'] += score - qbScore
else:
# find the lowest score between the flex and that player's position to see who is replaced
lowPositionScore = 0
for playerName in lineup_data['l']['FLEX']:
lowPositionScore = lineup_data['l']['FLEX'][playerName]
break
for playerName in lineup_data['l'][position]:
if lineup_data['l'][position][playerName] < lowPositionScore:
lowPositionScore = lineup_data['l'][position][playerName]
if lowPositionScore < score:
lineup_data['s'] += score - lowPositionScore
def get_player_to_swap(lineup, test_player, test_player_adp, test_player_position):
same_team_same_position_players = []
for player in lineup[test_player_position]:
same_team_same_position_players.append(
{'name': player['name'], 'adp_difference': abs(player['pick'] - test_player_adp)})
# If no such players exist, return None
if len(same_team_same_position_players) == 0:
return None
same_team_same_position_players.sort(key=lambda x: x['adp_difference'])
player_to_swap = same_team_same_position_players[0]['name']
return player_to_swap
def getPlayersToSwap(playerAdpVals, position, playerId, pickNum, playerNamesById, playerAdps):
numPlayers = getNumPlayersToSwap(pickNum)
offset = 0
for id in playerAdpVals:
if playerAdpVals[id] > pickNum:
break
offset += 1
playersToSwap = []
ids = list(playerAdpVals.keys())
startVal = max(0, offset-numPlayers)
endVal = min(len(ids)-1, offset + numPlayers)
for i in range(startVal, endVal+1):
if startVal < 0 or endVal >= len(ids):
continue
id = ids[i]
if playerId == id:
continue
playerName = playerNamesById[id]
if playerName not in playerAdps:
continue
playerVals = playerAdps[playerName]
if playerVals['p'] != position:
continue
playersToSwap.append(playerName)
return playersToSwap
def getNumPlayersToSwap(pickNum):
roundNum = round((pickNum-1) / 12) + 1
if roundNum <= 2:
return 3
else:
return 3 + (roundNum - 2)
def calculate_rank(new_team_data, precalc_data):
# The new team's draft ID
new_team_draft_id = new_team_data['draft_id']
# Extract all teams in the same draft from precalc_data
same_draft_teams = [team for team in precalc_data if team['draft_id'] == new_team_draft_id]
# Calculate total score for new team
new_team_total_score = sum(week_data['score'] for week_data in new_team_data['team_output'])
# Add new team to the list of same draft teams
same_draft_teams.append({'team_id': new_team_data['team_id'], 'total_score': new_team_total_score})
# Sort teams by total score in descending order
sorted_teams = sorted(same_draft_teams, key=lambda x: x['total_score'], reverse=True)
# Find rank of new team
new_team_rank = next(
i + 1 for i, team in enumerate(sorted_teams) if team['team_id'] == new_team_data['team_id'])
return new_team_rank
if __name__ == '__main__':
con = sqlite3.connect('bestball.db')
playerAdps = {}
f = open('playerAdps.json', 'r')
playerAdps = json.loads(f.read())
f.close()
playerAdps = dict(sorted(playerAdps.items(), key=lambda x: x[1]['a']))
playerIds = {}
f = open('playerIds.datajson', 'r')
playerIds = json.loads(f.read())
f.close()
playerNamesById = {}
for playerName in playerIds:
for playerId in playerIds[playerName]:
playerNamesById[playerId] = playerName
playerAdpsAllDates = {}
f = open('playerAdpData.datajson', 'r')
playerAdpsAllDates = json.loads(f.read())
f.close()
for date in playerAdpsAllDates:
playerAdpsAllDates[date] = dict(sorted(playerAdpsAllDates[date].items(), key=lambda x: x[1]))
# Dictionaries to store player scores and info
player_scores = {}
player_info = {}
# Fetch data from 'UD_FPTS_2022' table
UD_FPTS_2022_df = pd.read_sql_query("SELECT * FROM UD_FPTS_2022", con)
BATCH_SIZE = 1
# Set up a dictionary to store advance counts for each player
advance_count = {player: {'a': 0, 't': 0} for player in playerAdps.keys()}
# so that we don't have to recalculate lineups
player_results = {}
try:
f = open('playerResults.json', 'r')
player_results = json.loads(f.read())
f.close()
except:
pass
try:
f = open('advanceRate.json', 'r')
advance_count = json.loads(f.read())
f.close()
except:
pass
# Load the data
'''
with open(r'precalc_data.json', 'r') as file:
precalc_data = json.load(file)
'''
for i in range(1, 11):
f = open('precalc_data_new_%d.json' % (i,), 'r')
precalc_data = []
while True:
line = f.readline()
if not line:
break
precalc_data.append(json.loads(line))
f.close()
# Main loop
for test_player in playerAdps:
if playerAdps[test_player]['a'] >= 200:
continue
if test_player not in player_results:
player_results[test_player] = []
test_player_position = playerAdps[test_player]['p']
if test_player not in advance_count:
continue
print(f"Player to test: {test_player}")
playerCount = 1
# Get the weekly scores of the test player from the 'UD_FPTS_2022' table
test_player_scores_dict = get_scores_for_player(test_player)
if not test_player_scores_dict:
continue
for val in precalc_data:
for draftId in val:
break
draftData = val[draftId]
for lineupId in draftData:
if lineupId in player_results[test_player]:
continue
lineupData = draftData[lineupId]
original_rank = lineupData["rank"]
#print(f"Original rank: {original_rank}")
# If the test player is already on the team, continue to the next player
playerFound = False
for player in lineupData['lineup'][test_player_position]:
if player['name'] == test_player:
playerFound = True
break
if playerFound:
if lineupData['rank'] <= 2:
advance_count[test_player]['a'] += 1
advance_count[test_player]['t'] += 1
if playerCount % 5000 == 0:
print(playerCount)
player_results[test_player].append(lineupId)
f = open('playerResults.json', 'w')
f.write(json.dumps(player_results))
f.flush()
f.close()
f = open('advanceRate.json', 'w')
f.write(json.dumps(advance_count))
f.flush()
f.close()
playerCount += 1
continue
# Get the player to swap with the test player
playerAdpsByDate = playerAdpsAllDates[lineupData['date']]
try:
playerId = playerIds[test_player][0]
playerAdp = playerAdpsByDate[playerId]
except:
try:
playerAdp = playerAdps[test_player]['a']
except:
playerAdp = 216
player_to_swap = get_player_to_swap(lineupData['lineup'], test_player, playerAdp,
playerAdps[test_player]['p'])
if not player_to_swap:
continue
#(f"Player to swap: {player_to_swap}")
# Swap the player
new_team_data = swap_player(lineupData, player_to_swap, test_player, test_player_scores_dict,
test_player_position)
#print(f"New team data: {new_team_data}")
if new_team_data['total_score'] > val['second']:
advance_count[test_player]['a'] += 1
advance_count[test_player]['t'] += 1
player_results[test_player].append(lineupId)
if playerCount % 5000 == 0:
print(playerCount)
f = open('playerResults.json', 'w')
f.write(json.dumps(player_results))
f.flush()
f.close()
f = open('advanceRate.json', 'w')
f.write(json.dumps(advance_count))
f.flush()
f.close()
playerCount += 1
'''
# Calculate the new rank
new_rank = calculate_rank(new_team_data, precalc_data)
print(f"New rank: {new_rank}")
# If the new rank is better than the original rank, increment the advance count for the test player
if new_rank < original_rank:
advance_count[test_player] += 1
original_rank = new_rank
'''
# break
f = open('playerResults.json', 'w')
f.write(json.dumps(player_results))
f.flush()
f.close()
f = open('advanceRate.json', 'w')
f.write(json.dumps(advance_count))
f.flush()
f.close()
playerPointsPercentages = {}
try:
f = open('playerPointsPercentages.json', 'r')
playerPointsPercentages = json.loads(f.read())
f.close()
except:
pass
playersAdvancingPointsPercentages = {}
try:
f = open('playerAdvancingPointsPercentages.json', 'r')
playersAdvancingPointsPercentages = json.loads(f.read())
f.close()
except:
pass
completedContests = []
try:
f = open('playerAdvancingPointsPercentagesCompletedContests.json', 'r')
completedContests = json.loads(f.read())
f.close()
except:
pass
nameExceptions = {
'D.J. Moore': 'DJ Moore',
'A.J. Dillon': 'AJ Dillon',
'D.J. Chark': 'DJ Chark',
'K.J. Hamler': 'KJ Hamler',
'Gabe Davis': 'Gabriel Davis'
}
for i in range(1, 11):
f = open('precalc_data_new_%d.json' % (i,), 'r')
precalc_data = []
while True:
line = f.readline()
if not line:
break
precalc_data.append(json.loads(line))
f.close()
for val in precalc_data:
for draftId in val:
break
if draftId in completedContests:
continue
print(f"Calculting draft: {draftId}")
valCount = 1
draftData = val[draftId]
for lineupId in draftData:
playerScores = {}
lineup = draftData[lineupId]['lineup']
for position in lineup:
for val in lineup[position]:
playerName = val['name']
playerScores[playerName] = 0
totalPoints = draftData[lineupId]['total_score']
weeklyScores = draftData[lineupId]['team_output']
for weekNum in weeklyScores:
weeklyLineup = weeklyScores[weekNum]['l']
for position in weeklyLineup:
for playerName in weeklyLineup[position]:
score = weeklyLineup[position][playerName]
if playerName in nameExceptions:
playerName = nameExceptions[playerName]
playerScores[playerName] += score
rank = draftData[lineupId]['rank']
for playerName in playerScores:
if playerName not in playerPointsPercentages:
playerPointsPercentages[playerName] = {'p': 0, 't': 0}
playerPointsPercentages[playerName]['p'] += playerScores[playerName]
playerPointsPercentages[playerName]['t'] += totalPoints
if rank <= 2:
if playerName not in playersAdvancingPointsPercentages:
playersAdvancingPointsPercentages[playerName] = {'p': 0, 't': 0}
playersAdvancingPointsPercentages[playerName]['p'] += playerScores[playerName]
playersAdvancingPointsPercentages[playerName]['t'] += totalPoints
completedContests.append(draftId)
if valCount % 5000 == 0:
print(valCount)
f = open('playerPointsPercentages.json', 'w')
f.write(json.dumps(playerPointsPercentages))
f.flush()
f.close()
f = open('playerAdvancingPointsPercentages.json', 'w')
f.write(json.dumps(playersAdvancingPointsPercentages))
f.flush()
f.close()
f = open('playerAdvancingPointsPercentagesCompletedContests.json', 'w')
f.write(json.dumps(completedContests))
f.flush()
f.close()
valCount += 1
f = open('playerPointsPercentages.json', 'w')
f.write(json.dumps(playerPointsPercentages))
f.flush()
f.close()
f = open('playerAdvancingPointsPercentages.json', 'w')
f.write(json.dumps(playersAdvancingPointsPercentages))
f.flush()
f.close()
f = open('playerAdvancingPointsPercentagesCompletedContests.json', 'w')
f.write(json.dumps(completedContests))
f.flush()
f.close()
# so that we don't have to recalculate lineups
lineupsCalculated = []
try:
f = open('lineupsCalculatedPerLineupAdvanceRate.json', 'r')
lineupsCalculated = json.loads(f.read())
f.close()
except:
pass
playerPointsAddedPerLineup = {}
try:
f = open('playerPointsAddedPerLineup.json', 'r')
playerPerLineupAdvanceRate = json.loads(f.read())
f.close()
except:
pass
playerScoresVals = {}
for i in range(1, 11):
f = open('precalc_data_new_%d.json' % (i,), 'r')
precalc_data = []
while True:
line = f.readline()
if not line:
break
precalc_data.append(json.loads(line))
f.close()
# Main loop
for contestData in precalc_data:
for contestId in contestData:
break
if contestId in lineupsCalculated:
continue
print(f"Calculting draft: {contestId}")
valCount = 1
for lineupId in contestData[contestId]:
lineupInfo = contestData[contestId][lineupId]
lineup = lineupInfo['lineup']
weeklyScores = lineupInfo['team_output']
draftDate = lineupInfo['date']
playerAdpVals = playerAdpsAllDates[draftDate]
for position in lineup:
for playerVal in lineup[position]:
playerName = playerVal['name']
playerIdName = playerName
if playerIdName in nameExceptions:
playerIdName = nameExceptions[playerName]
if playerIdName not in playerIds:
continue
playerId = playerIds[playerIdName]
pickNum = playerVal['pick']
position = playerVal['pos']
playersToSwap = getPlayersToSwap(playerAdpVals, position, playerId[0], pickNum, playerNamesById, playerAdps)
if len(playersToSwap) == 0:
continue
for playerToSwap in playersToSwap:
if playerToSwap not in playerScoresVals:
playerScoresVals[playerToSwap] = get_scores_for_player(playerToSwap)
new_team_data = swap_player(lineupInfo, playerName, playerToSwap,
playerScoresVals[playerToSwap],
position)
if playerName not in playerPointsAddedPerLineup:
playerPointsAddedPerLineup[playerName] = {'pointsAdded' : 0, 'numSwaps' : 0, 'position' : position, 'totalAdp' : 0, 'totalLineups' : 0}
playerPointsAddedPerLineup[playerName]['numSwaps'] += 1
playerPointsAddedPerLineup[playerName]['pointsAdded'] += lineupInfo['total_score'] - new_team_data['total_score']
playerPointsAddedPerLineup[playerName]['totalAdp'] += pickNum
playerPointsAddedPerLineup[playerName]['totalLineups'] += 1
lineupsCalculated.append(contestId)
if valCount % 5000 == 0:
print(valCount)
f = open('lineupsCalculatedPerLineupAdvanceRate.json', 'w')
f.write(json.dumps(lineupsCalculated))
f.flush()
f.close()
f = open('playerPointsAddedPerLineup.json', 'w')
f.write(json.dumps(playerPointsAddedPerLineup))
f.flush()
f.close()
valCount += 1
f = open('lineupsCalculatedPerLineupAdvanceRate.json', 'w')
f.write(json.dumps(lineupsCalculated))
f.flush()
f.close()
f = open('playerPointsAddedPerLineup.json', 'w')
f.write(json.dumps(playerPointsAddedPerLineup))
f.flush()
f.close()
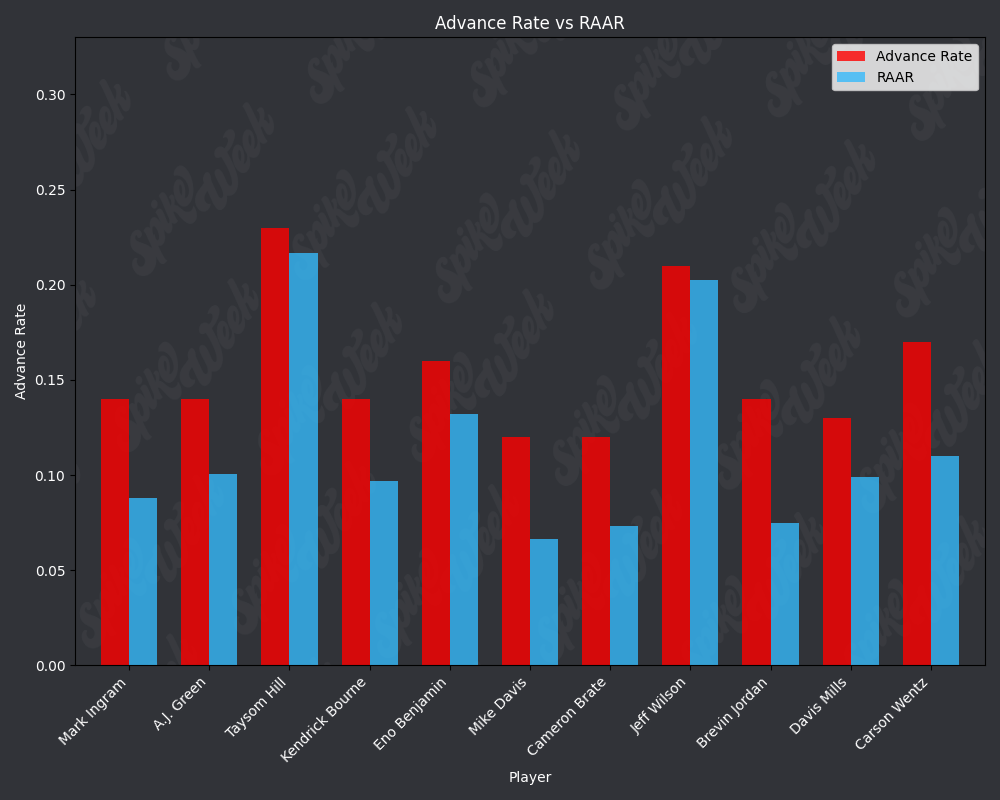
con.close()Now we compare the reported advance rate provided by Underdog for BBMIII to our roster agnostic advance rate.
import json
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# Load the JSON data
with open(r'advanceRate.json') as f:
data = json.load(f)
# Load the CSV data
csv_data = pd.read_csv(r'bbm3_adv_rate.csv')
# Normalize the player names in the csv data
csv_data['Player'] = csv_data['Player'].apply(lambda x: x.strip())
# Initialize a dictionary to store the a/t ratios
ratios = {}
# Iterate over items in the dictionary
for name, values in data.items():
a = values.get('a', 0)
t = values.get('t', 0)
if t != 0: # To avoid division by zero
ratios[name.strip()] = a / t
# Lists to store players, differences, percentage differences, ratios, and ADPs
players = []
diffs = []
perc_diffs = []
ratios_list = []
adps = []
adv_from_round_1 = []
# Iterate over each row in the CSV data
for _, row in csv_data.iterrows():
player = row['Player']
if player in ratios:
# Calculate the difference and the percentage difference
diff = ratios[player] - row['Adv From Round 1']
perc_diff = (diff / row['Adv From Round 1']) * 100 if row['Adv From Round 1'] != 0 else None
print(f"{player}: difference = {diff}, percentage difference = {perc_diff}%")
# Append the player, difference, percentage difference, ratio, ADP, and Adv From Round 1 to their respective lists
players.append(player)
diffs.append(diff)
perc_diffs.append(perc_diff)
ratios_list.append(ratios[player])
adps.append(row['ADP'])
adv_from_round_1.append(row['Adv From Round 1'])
else:
print(f"{player} does not exist in the JSON data")
# Convert lists to a DataFrame
df = pd.DataFrame({
'Player': players,
'Difference': diffs,
'Percentage Difference': perc_diffs,
'RAAR': ratios_list,
'ADP': adps,
'Advance Rate': adv_from_round_1
})
# Sort DataFrame by ADP for plotting
df_plot = df.sort_values('ADP')
# Plot each group of 24 players
n = 24
bar_width = 0.35
opacity = 0.8
for i in range(0, len(df_plot), n):
df_subset = df_plot.iloc[i:i + n]
fig, ax = plt.subplots(figsize=(10, 8))
index = np.arange(len(df_subset))
rects1 = plt.bar(index, df_subset['Advance Rate'], bar_width, alpha=opacity, color='r', label='Advance Rate')
rects2 = plt.bar(index + bar_width, df_subset['RAAR'], bar_width, alpha=opacity, color='#36bafb', label='RAAR')
plt.xlabel('Player', color='white')
plt.ylabel('Advance Rate', color='white')
plt.title('Advance Rate vs RAAR', color='white')
# Adjust x ticks to avoid cutting off the first bar
plt.xticks(index + bar_width / 2, df_subset['Player'], rotation=90, color='white', ha='right')
plt.yticks(color='white')
legend = plt.legend()
plt.setp(legend.get_texts(), color='black')
ax.set_facecolor('#313338')
fig.patch.set_facecolor('#313338')
img = Image.open(r'SW_watermark-1.png')
plt.imshow(img, aspect='auto', extent=(min(index) - 0.5, max(index) + bar_width + 0.5, 0, max(max(df_subset['Advance Rate']), max(df_subset['RAAR'])) + 0.1), alpha=0.5)
plt.tight_layout()
plt.show()
# Sort DataFrame by Difference in descending order for display
df_sorted = df.sort_values('Difference', ascending=False)
# Save the sorted DataFrame to a new CSV file
df_sorted.to_csv(r'sorted_difference.csv', index=False)
from IPython.display import display, Image
base_url = "https://raw.githubusercontent.com/sackreligious/bestballdatabowl/cdb0d53e05d15b3c7935315e1b9a12cadce82113/RAAR/R"
for i in range(1, 19, 2):
if i == 17:
img_url = f"{base_url}{i}.png"
else:
img_url = f"{base_url}{i}-{i+1}.png"
display(Image(url=img_url))
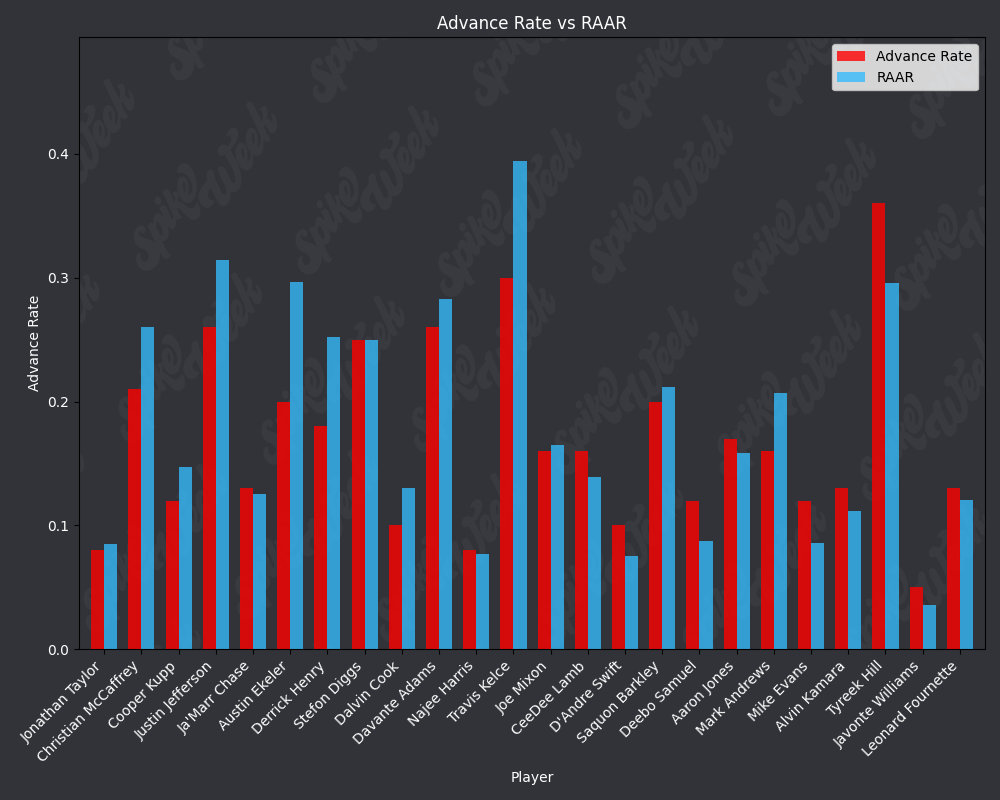
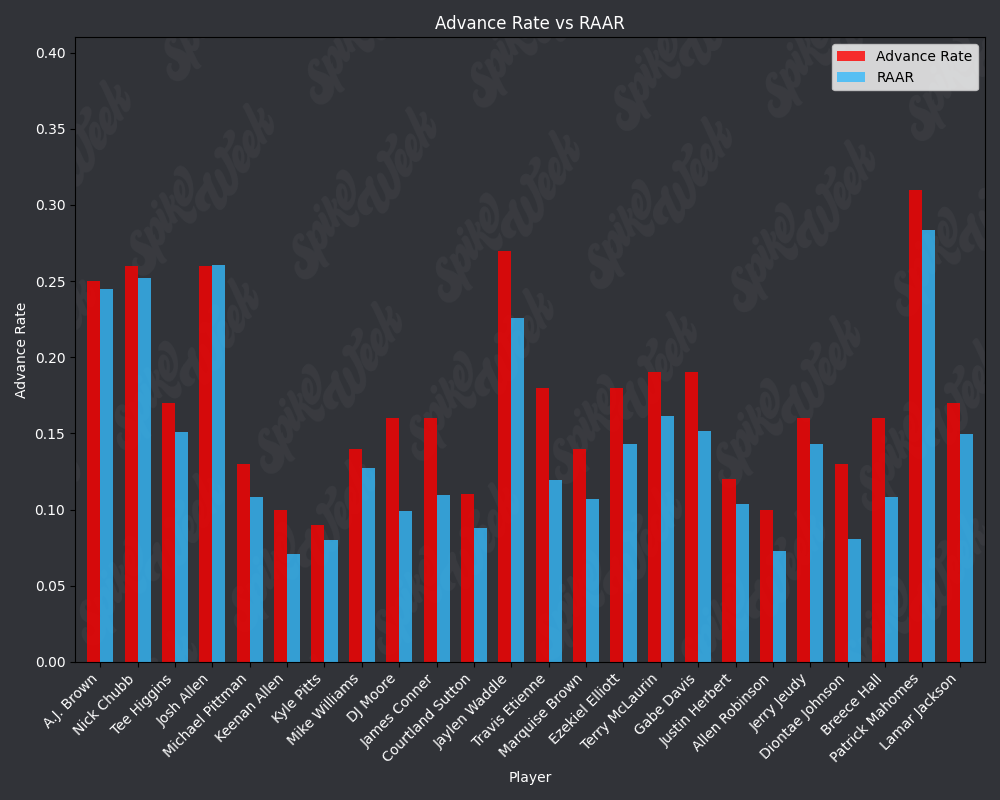
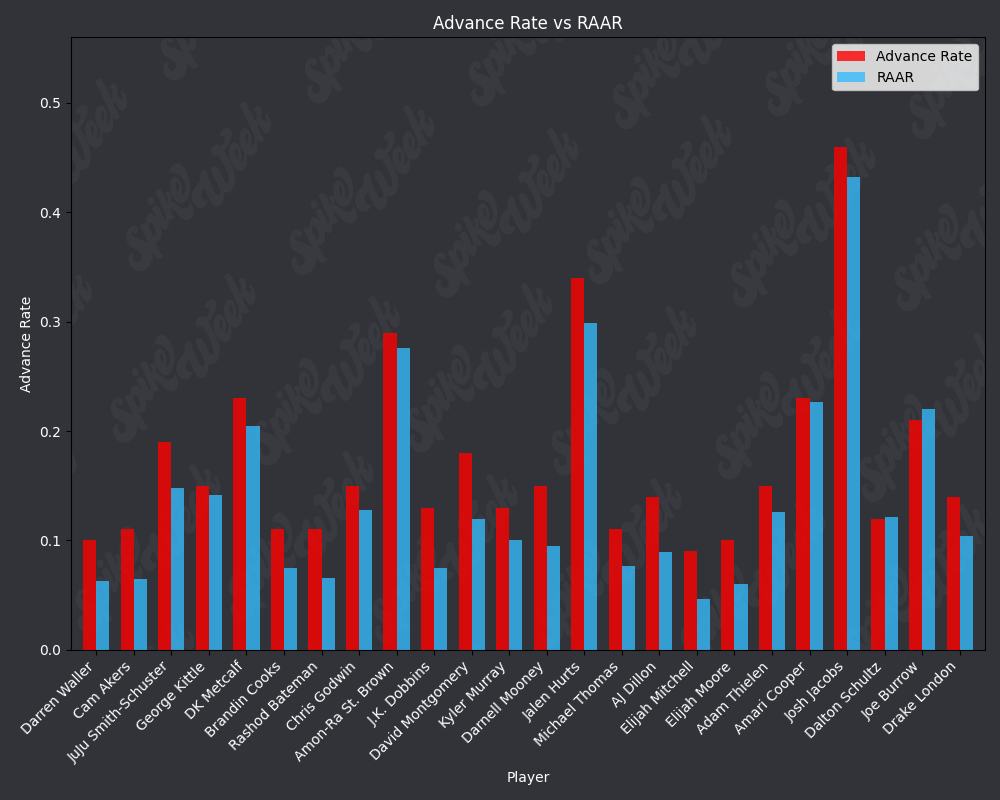
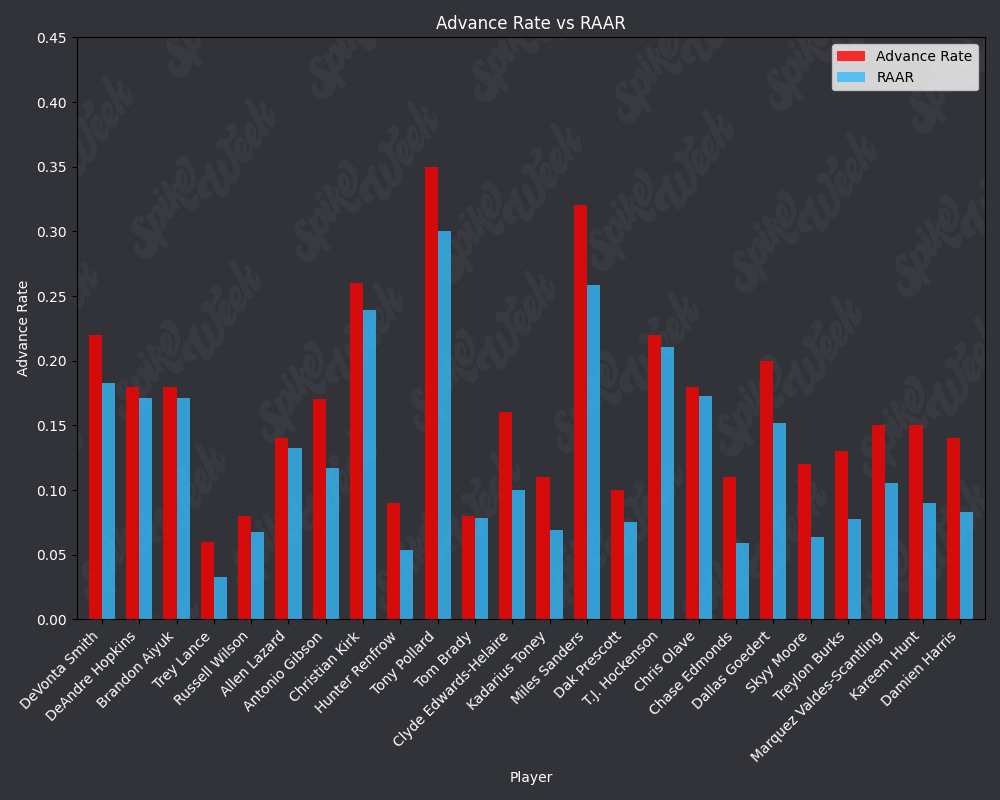
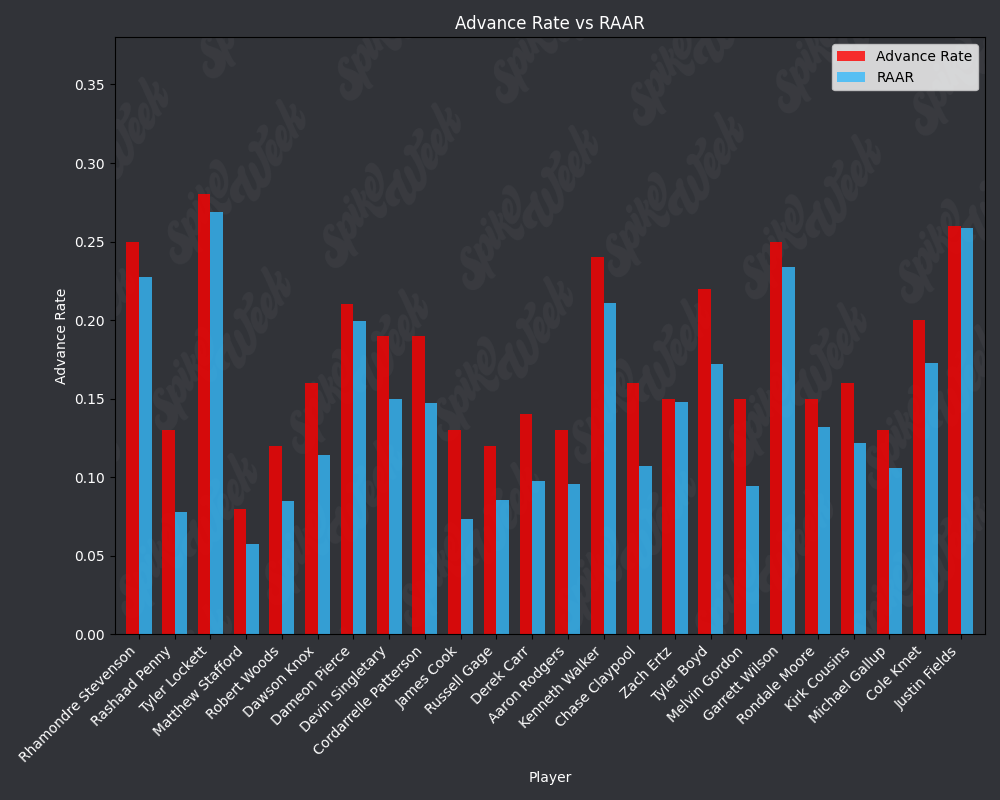
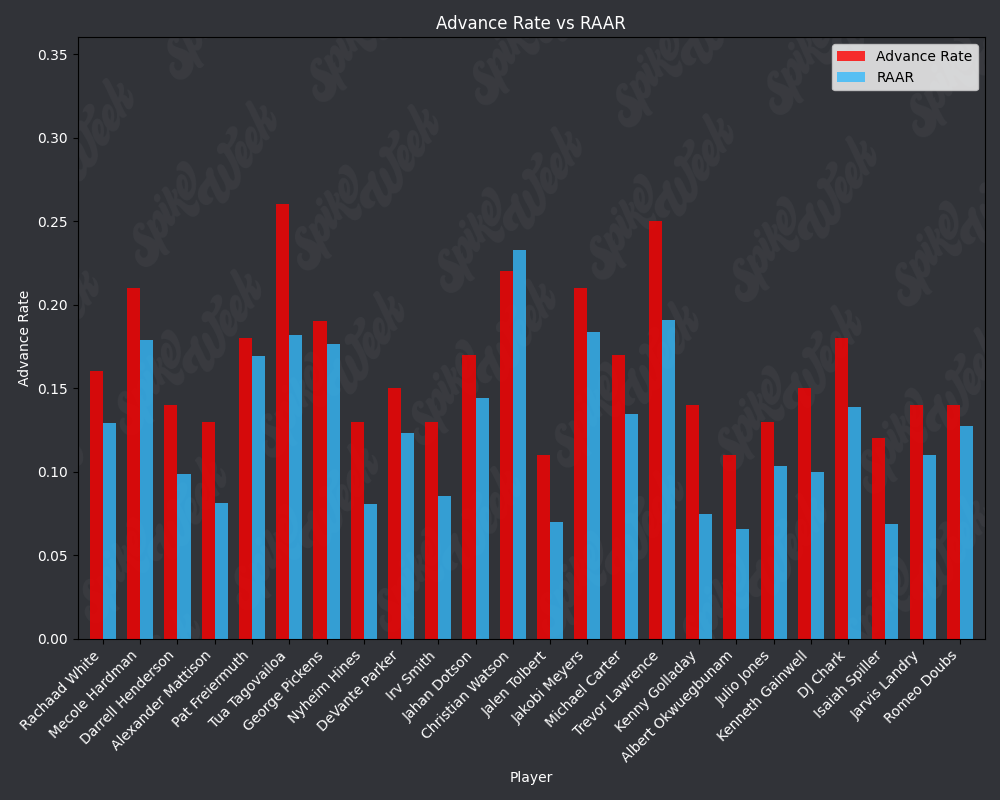
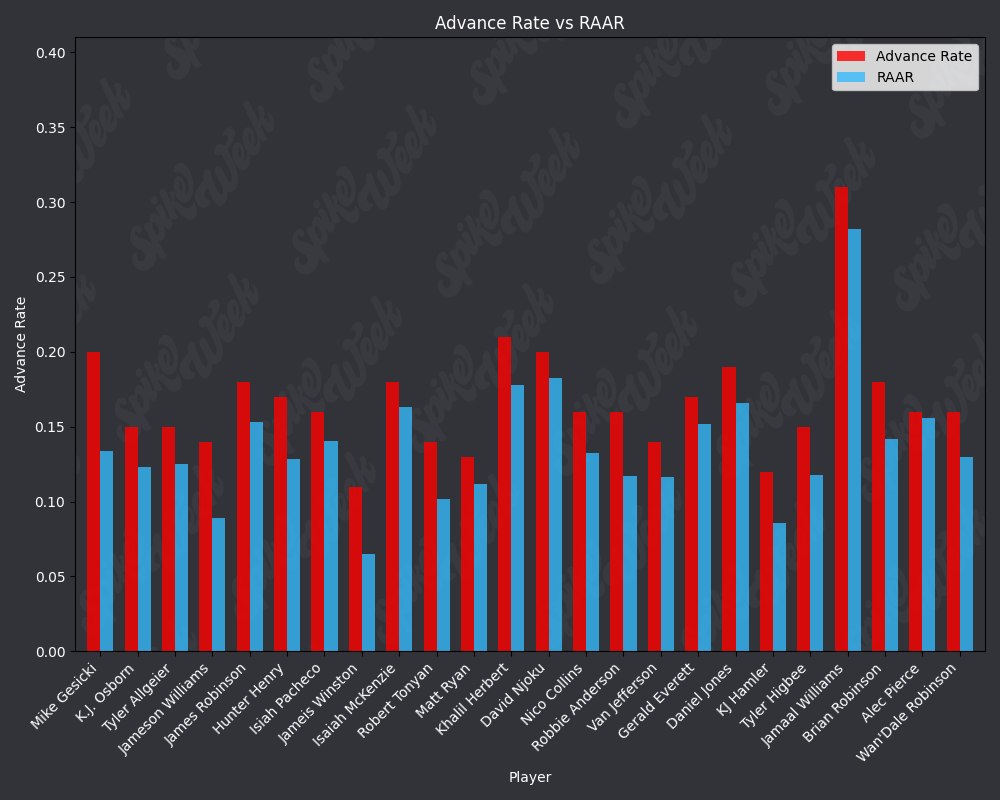
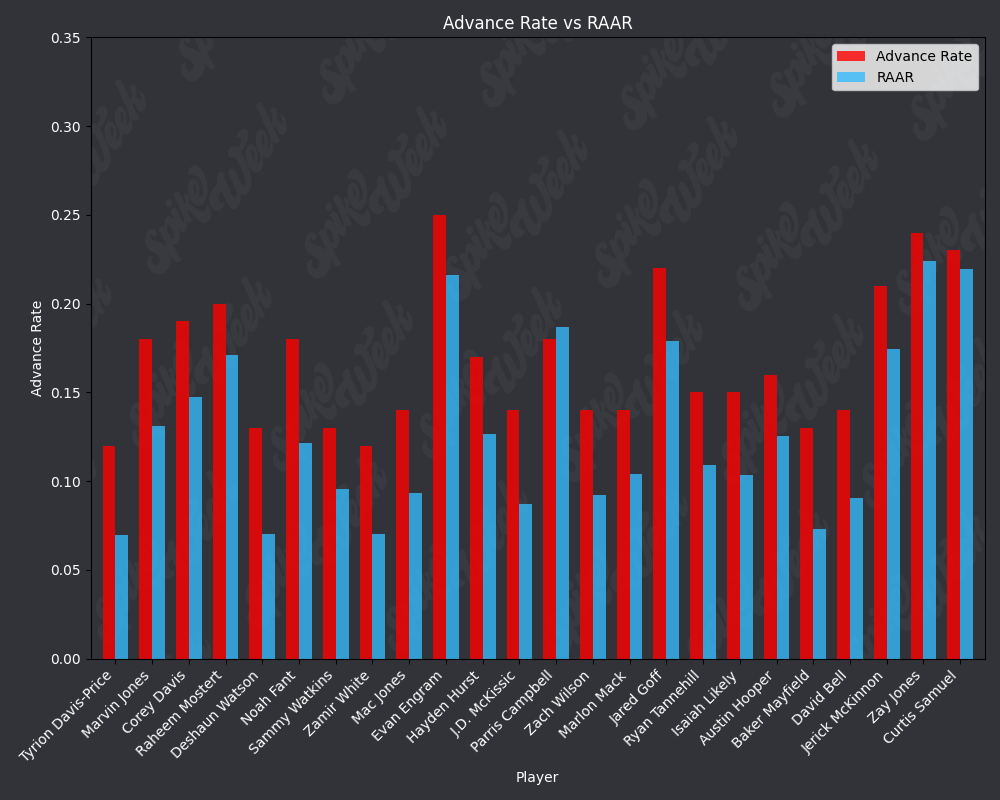
from IPython.display import display, Image
base_url = "https://raw.githubusercontent.com/sackreligious/bestballdatabowl/cdb0d53e05d15b3c7935315e1b9a12cadce82113/APPA/APPA_r"
for i in range(1, 19, 2):
img_url = f"{base_url}{i}-{i+1}.png"
display(Image(url=img_url))
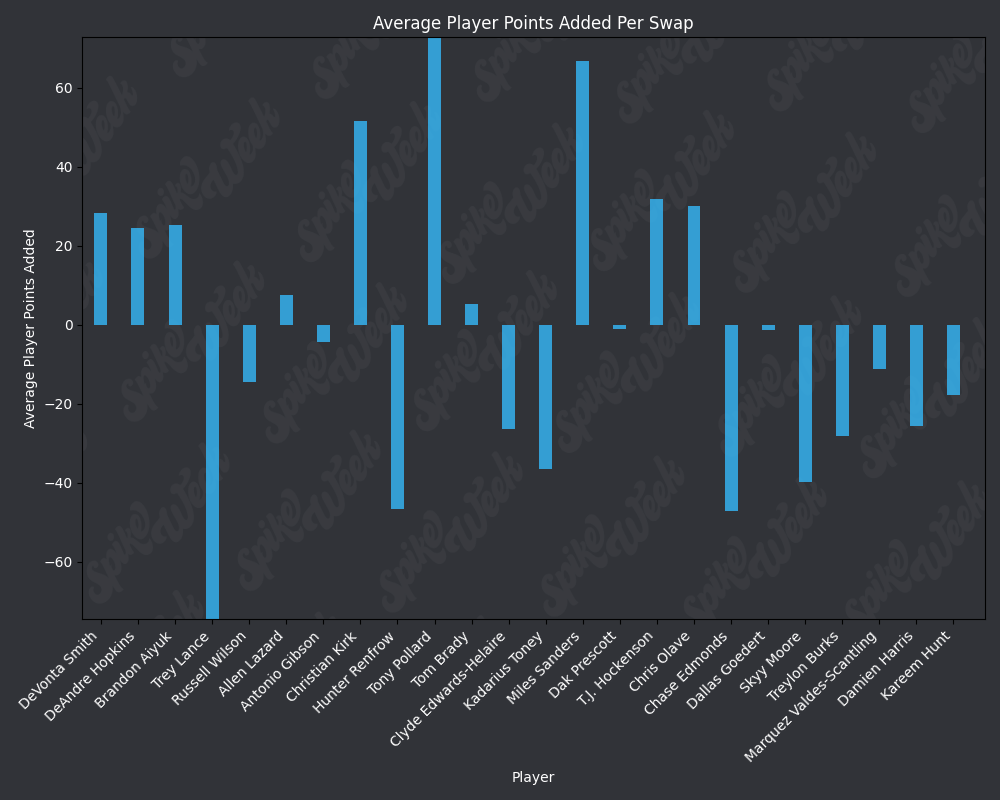
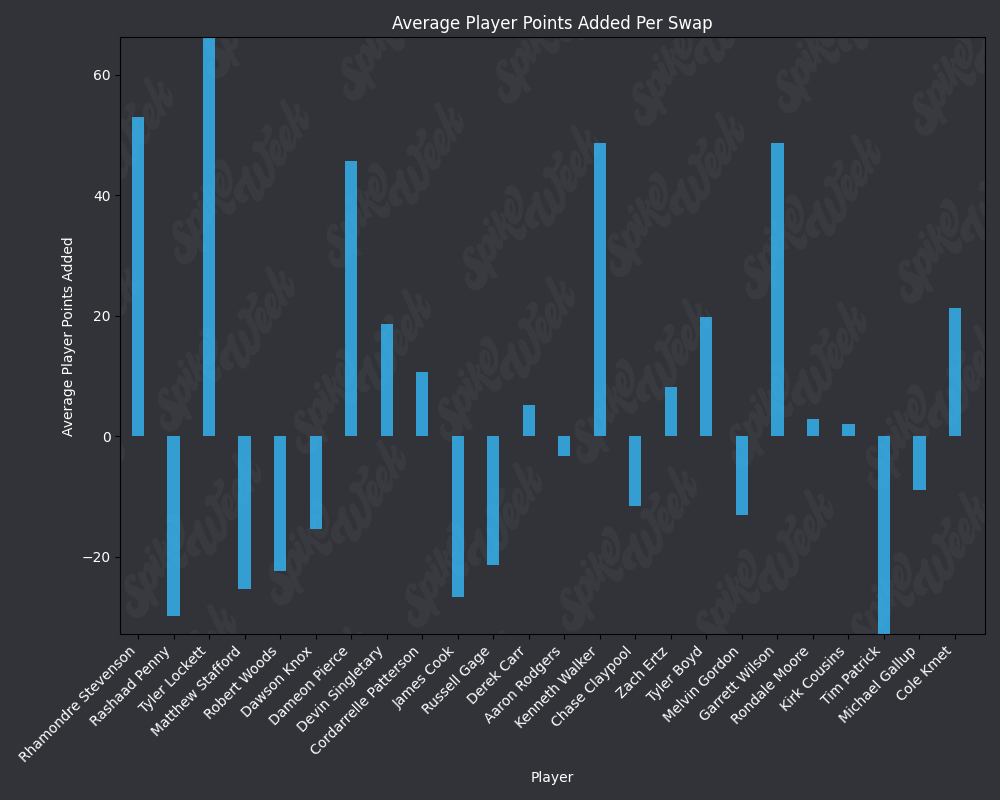
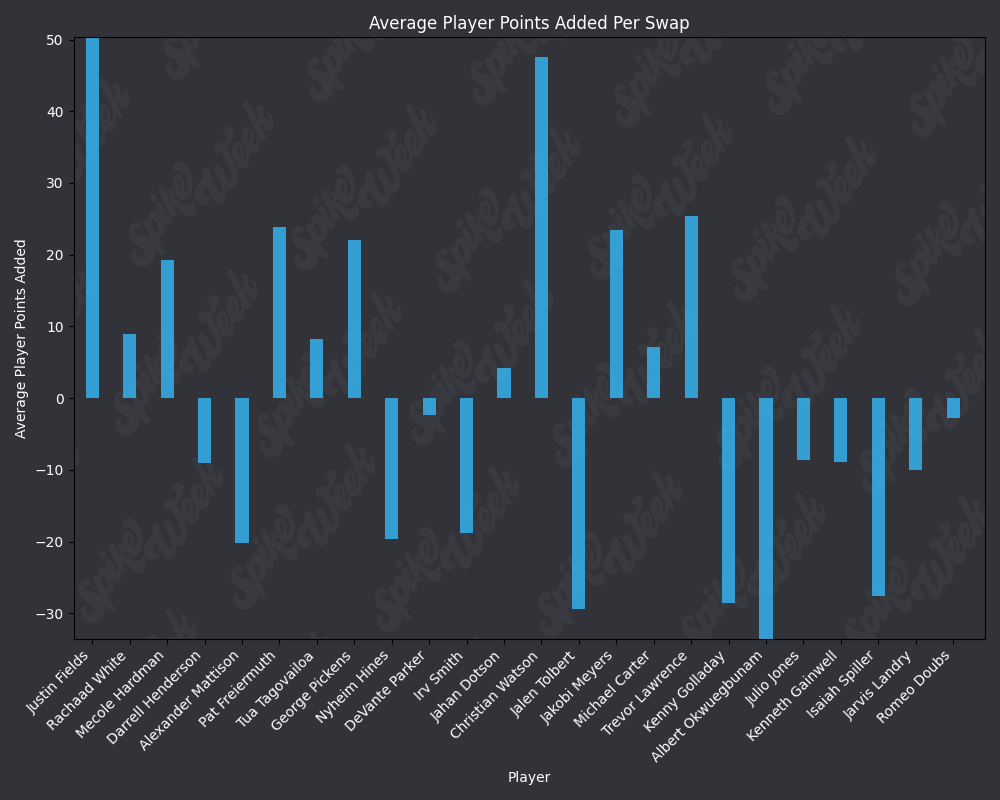
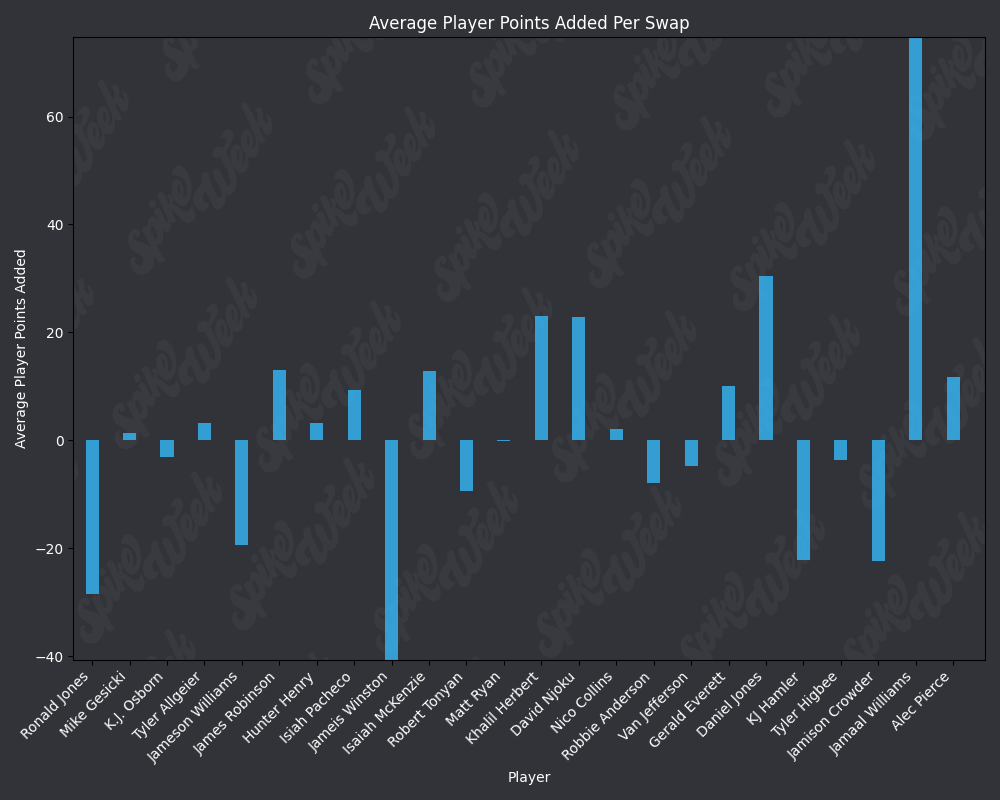
RAAR does have some limitations due to the methodology. For example, Travis Kelce sports an impressive RAAR differential of over 9% more than traditional advance rate. However, this is due to the player swapping protocol selecting players within a certain ADP range and of the same position as the target player. In practice, RAAR effectively pits Travis Kelce in a 1v1 with Mark Andrews, and we all know how that played out last season. Another feature of RAAR is the average RAAR is only 13.94% compared to tradtional advance rate average being 16.78%. This is because in order for a team to go from non-advancing to advancing, they must beat out one of the 2 teams that actually advanced. When the target player being added to rosters is a player with a very high advance rate, this can effectively turn the advance rate check into a 17 vs. 17 of the remaining players on each roster, assuming they both now contain the high advance rate target player. In summary, RAAR will have a bias towards underreporting advance rate because our measuring stick is the 2nd place team in each pod, a high threshold especially for teams in the bottom half of each pod.
Now that we've looked at RAAR and APPA, let's take a look at PPCAT and PPCT:
import json
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# Load the JSON data
with open(r'playerPointsAddedPerLineup.json') as f:
data = json.load(f)
# Load the CSV data
csv_data = pd.read_csv(r'bbm3_adv_rate.csv')
# Normalize the player names in the csv data
csv_data['Player'] = csv_data['Player'].apply(lambda x: x.strip())
# Initialize a list to store dictionaries with player information
player_info = []
# Iterate over items in the dictionary
for name, values in data.items():
num_swaps = values.get('numSwaps', 0)
points_added = values.get('pointsAdded', 0)
avg_points = points_added / num_swaps
# Get the player's ADP from the CSV data, if available
adp = csv_data.loc[csv_data['Player'] == name, 'ADP'].values[0] if name in csv_data['Player'].values else None
# Create a dictionary with player information and append it to the list
player_info.append({'player': name, 'avg_points_added': avg_points, 'adp': adp})
# Convert list of dictionaries to a DataFrame
df = pd.DataFrame(player_info)
# Sort DataFrame by ADP
df_sorted = df.sort_values('adp')
# Convert DataFrame columns back to lists
players = df_sorted['player'].tolist()
avg_points_added = df_sorted['avg_points_added'].tolist()
# Plot each group of 24 players
n = 24
bar_width = 0.35
opacity = 0.8
for i in range(0, len(players), n):
fig, ax = plt.subplots(figsize=(10, 8))
player_subset = players[i:i+n]
avg_points_subset = avg_points_added[i:i+n]
index = np.arange(len(player_subset))
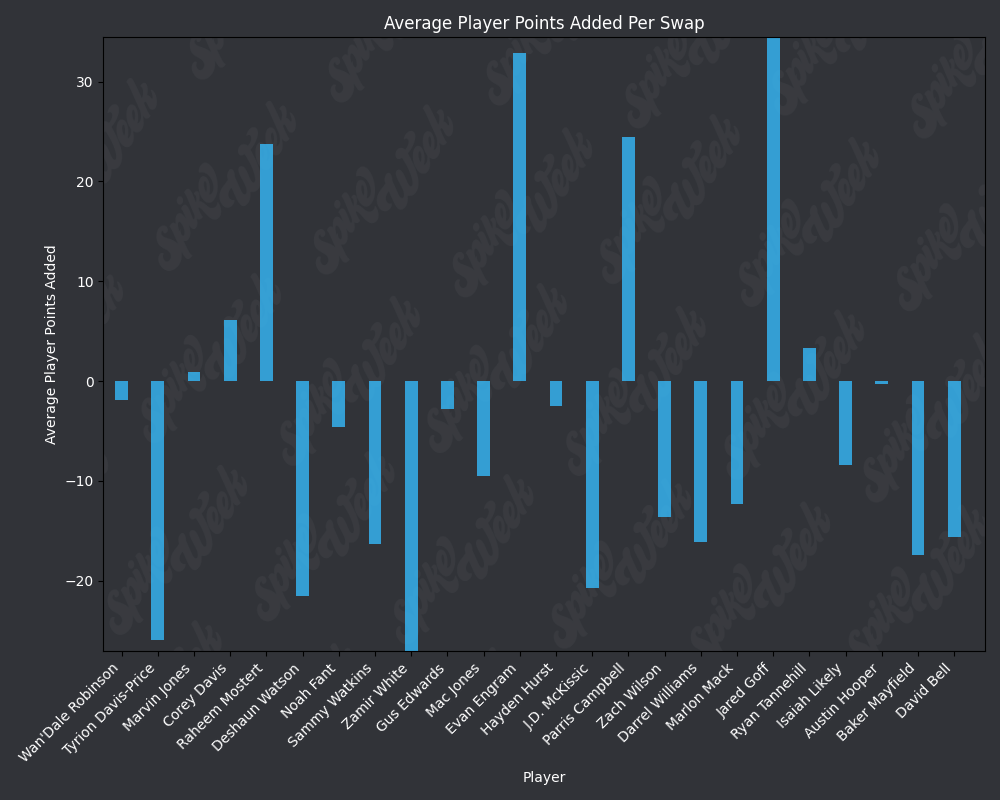
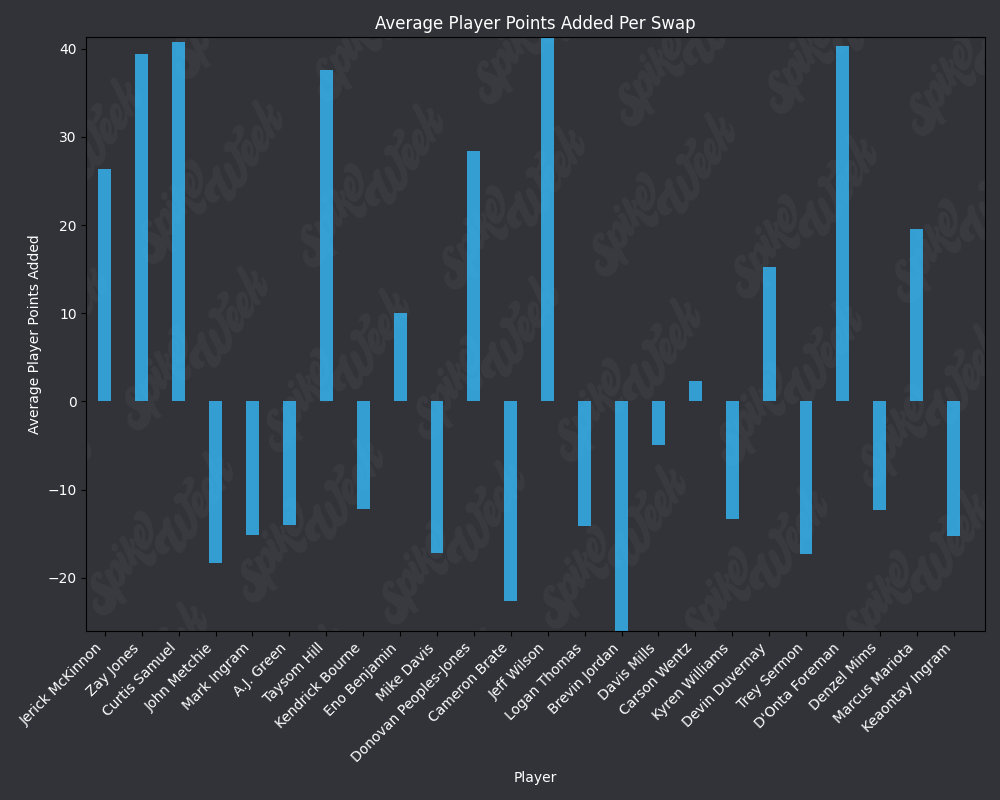
plt.bar(index, avg_points_subset, bar_width, alpha=opacity, color='#36bafb')
plt.xlabel('Player', color='white')
plt.ylabel('Average Player Points Added', color='white')
plt.title('Average Player Points Added Per Swap', color='white')
# Adjust x ticks to avoid cutting off the first bar
plt.xticks(index, player_subset, rotation=45, color='white', ha='right')
plt.yticks(color='white')
ax.set_facecolor('#313338')
fig.patch.set_facecolor('#313338')
img = Image.open(r'SW_watermark-1.png')
plt.imshow(img, aspect='auto', extent=(min(index) - 0.5, max(index) + bar_width + 0.5, min(avg_points_subset), max(avg_points_subset) + 0.1), alpha=0.5)
plt.tight_layout()
plt.show()
from IPython.display import display, Image
base_url = "https://raw.githubusercontent.com/sackreligious/bestballdatabowl/cdb0d53e05d15b3c7935315e1b9a12cadce82113/PPCAT/PPCAT_r"
for i in range(1, 19, 2):
img_url = f"{base_url}{i}-{i+1}.png"
display(Image(url=img_url))
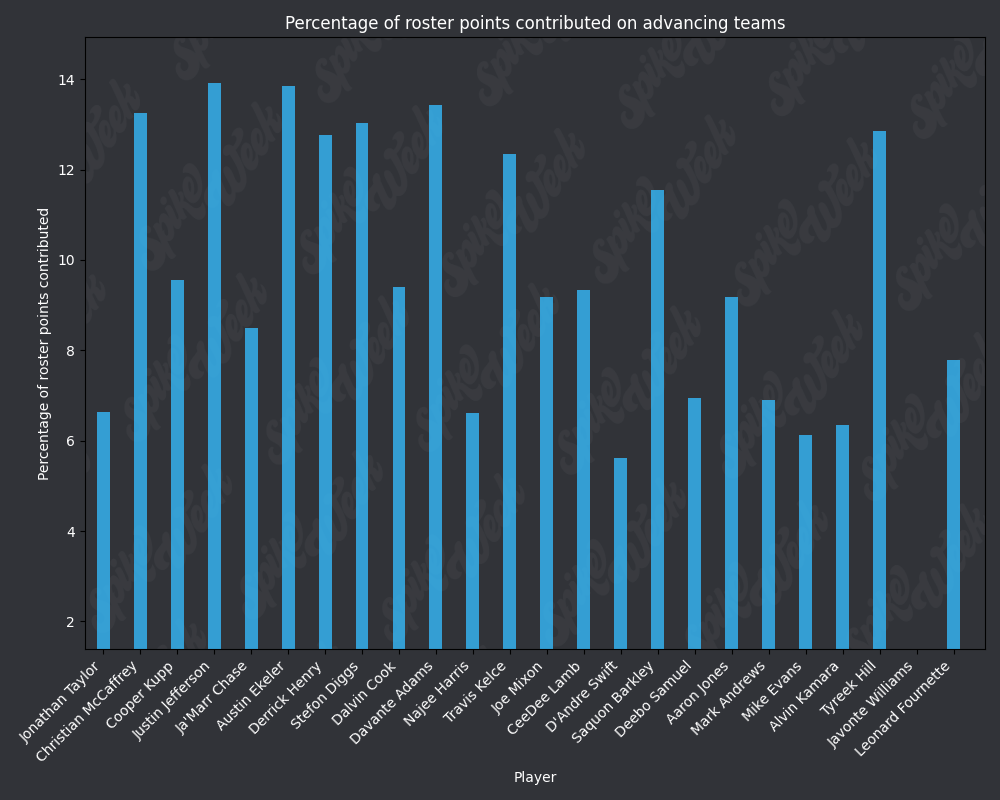
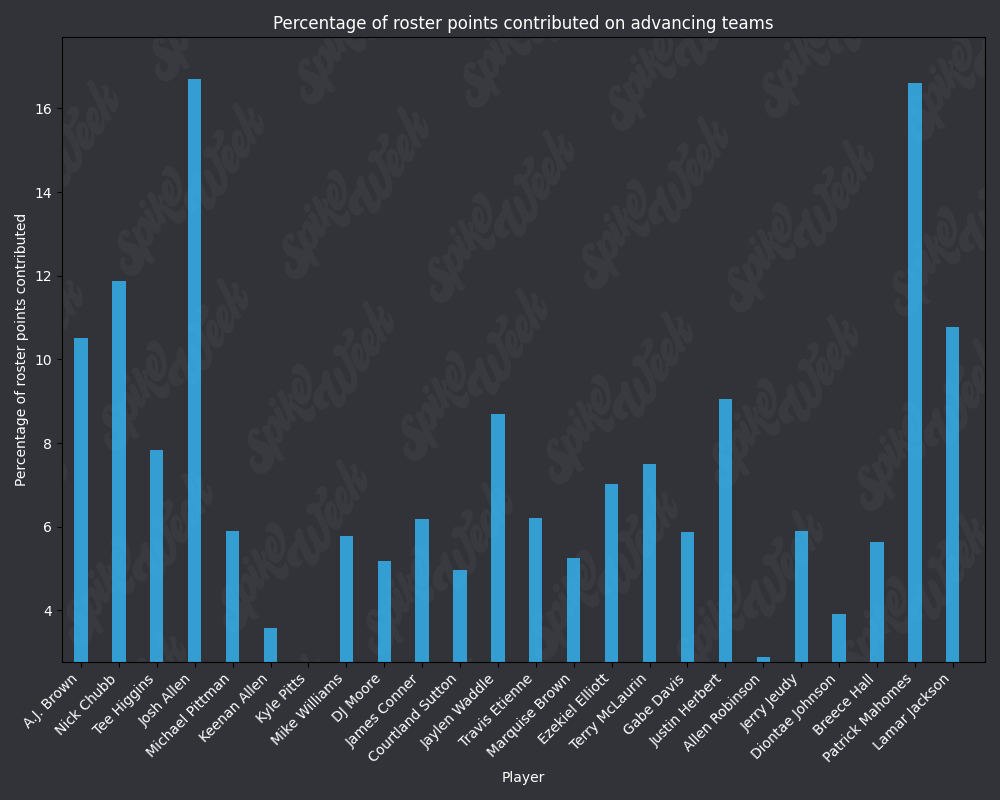
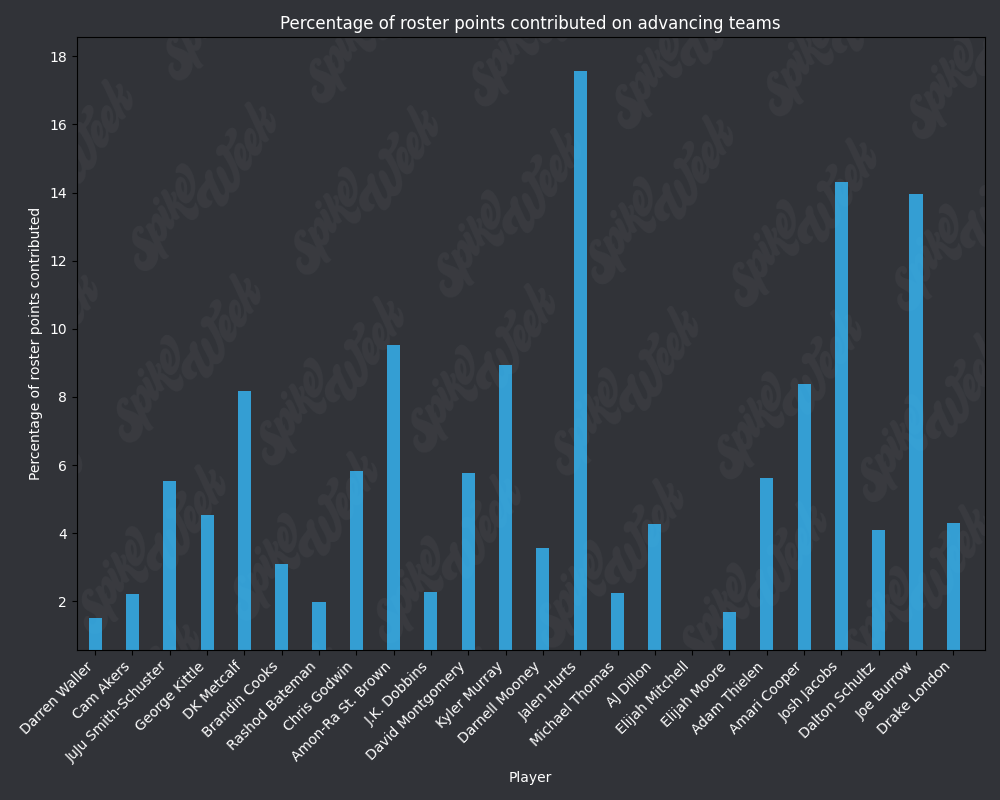
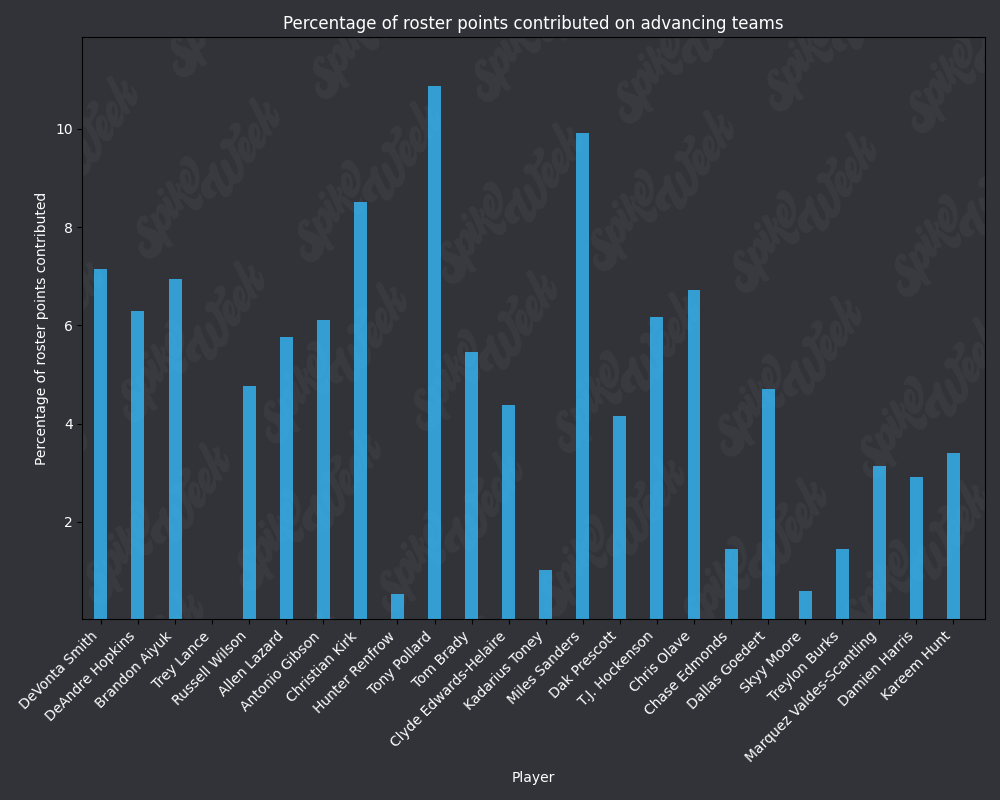
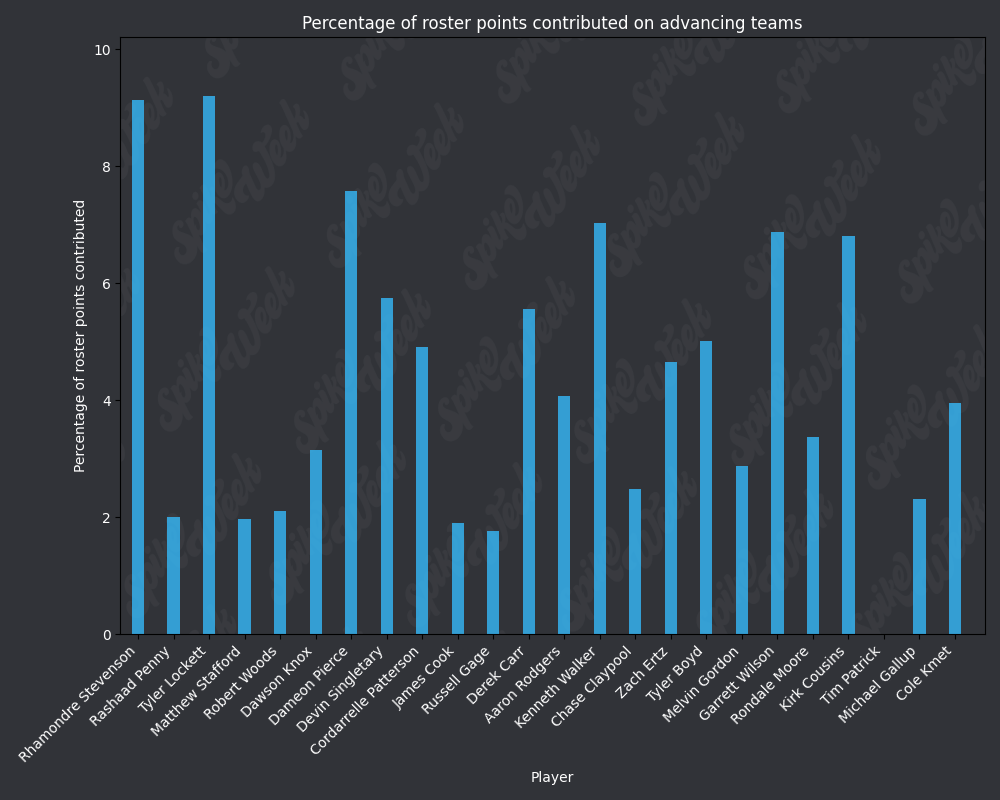
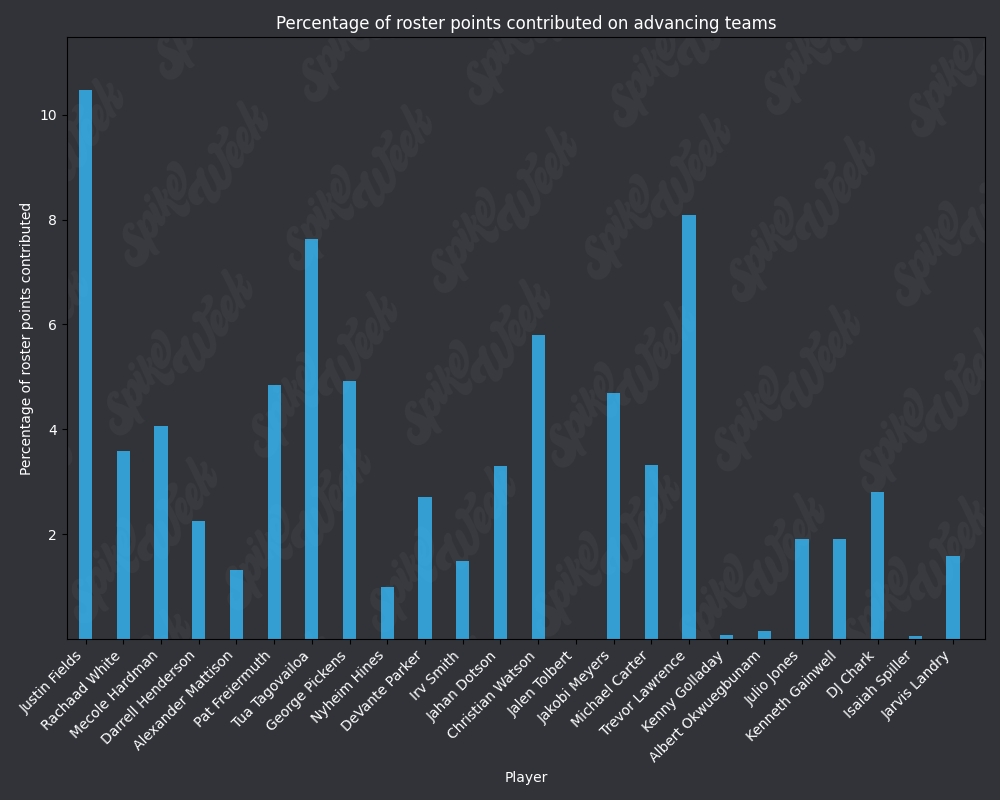
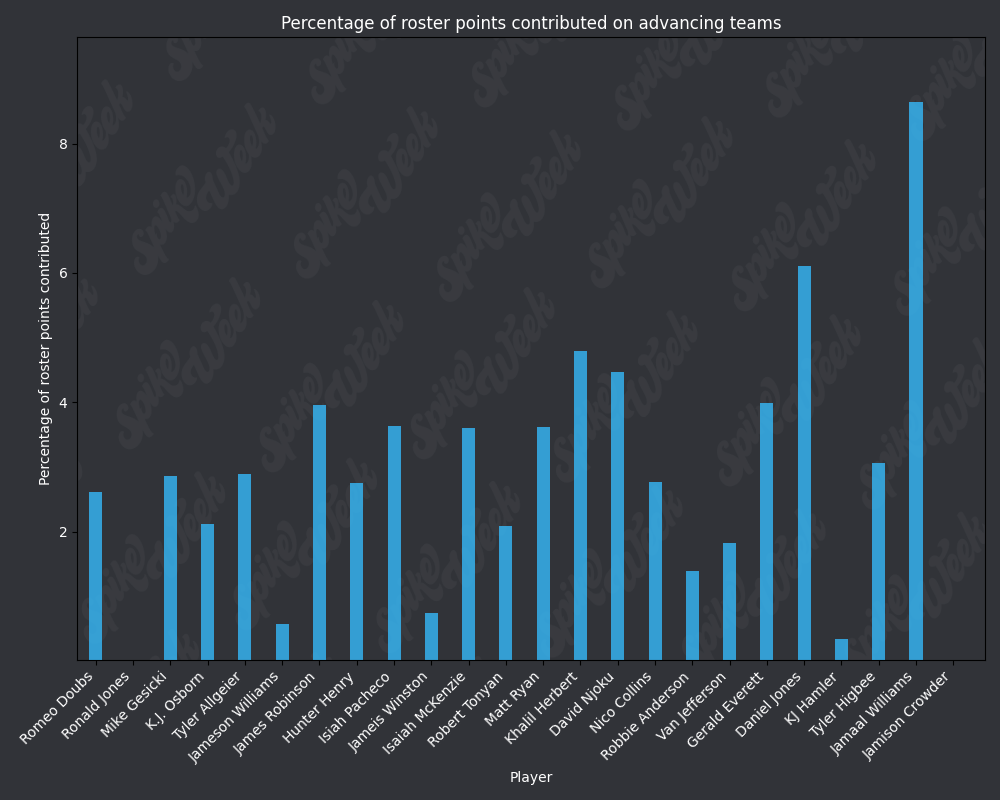
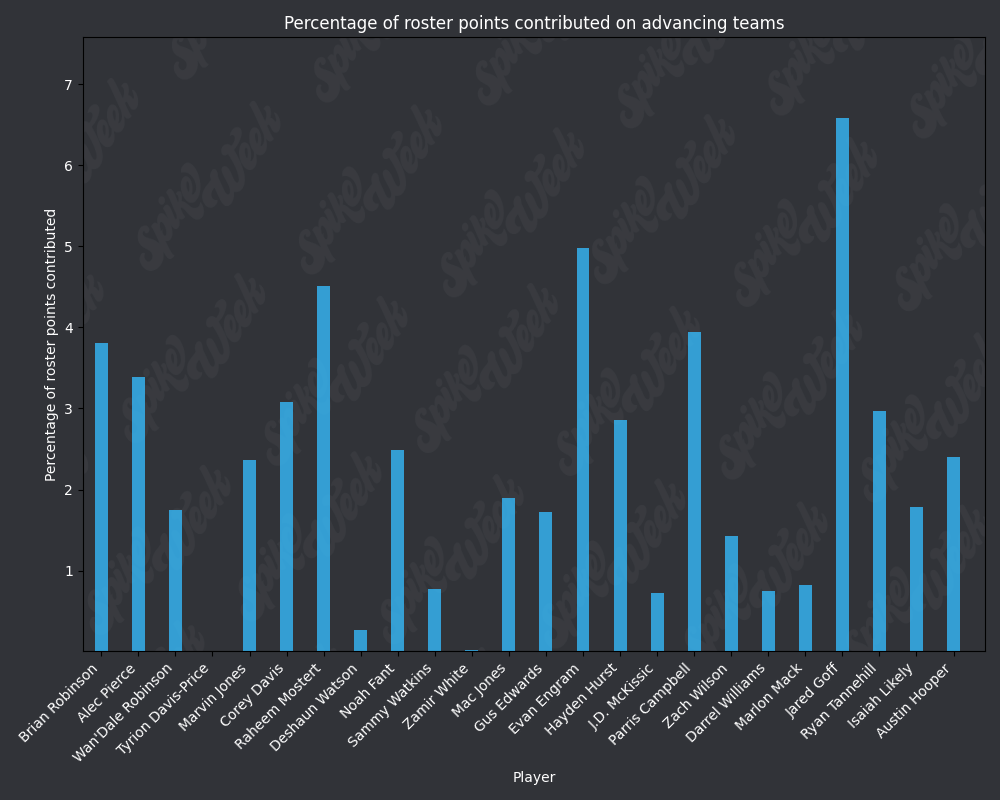
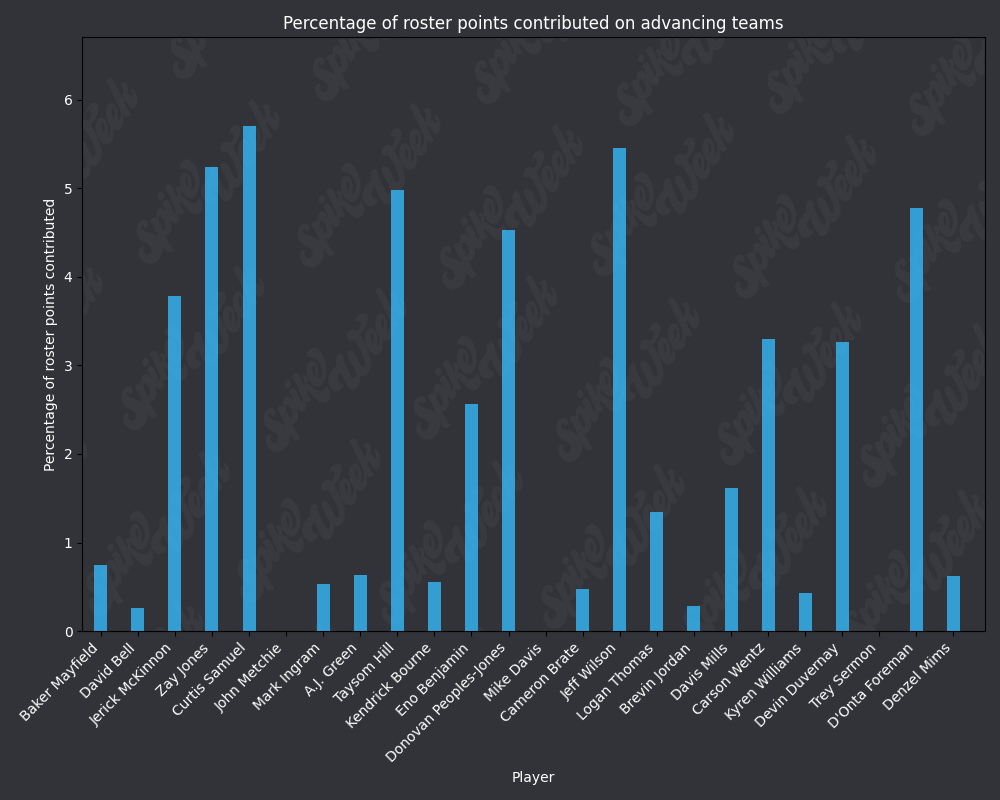
from IPython.display import display, Image
base_url = "https://raw.githubusercontent.com/sackreligious/bestballdatabowl/cdb0d53e05d15b3c7935315e1b9a12cadce82113/PPCT/PPCT_r"
for i in range(1, 19, 2):
img_url = f"{base_url}{i}-{i+1}.png"
display(Image(url=img_url))
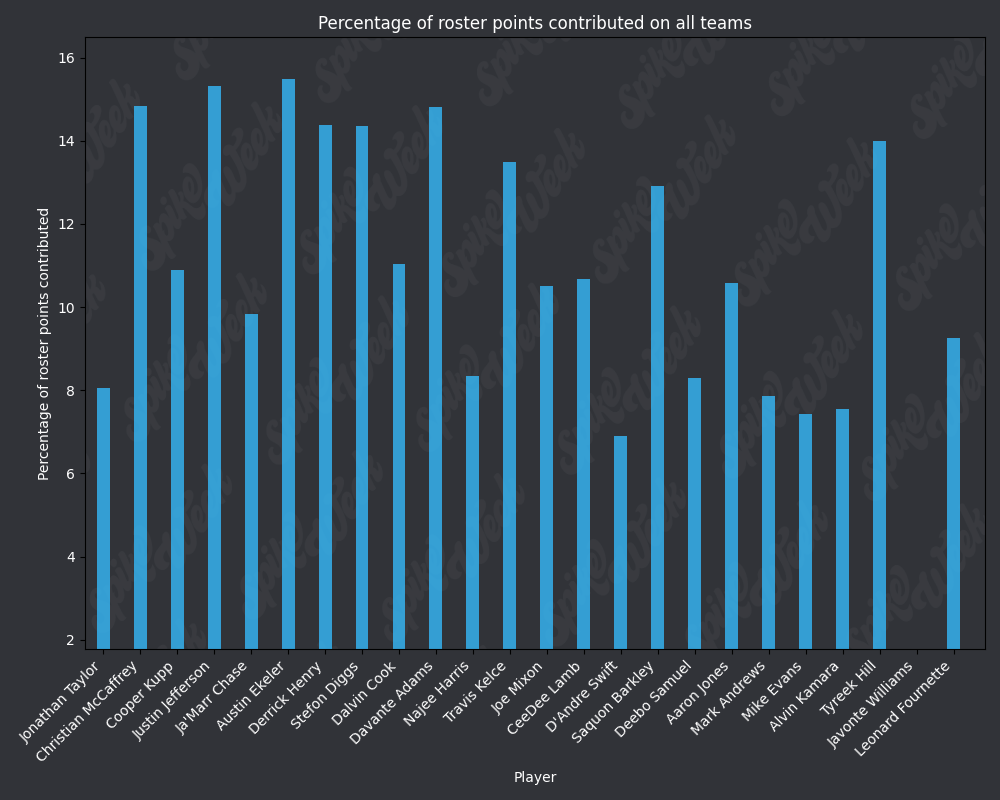
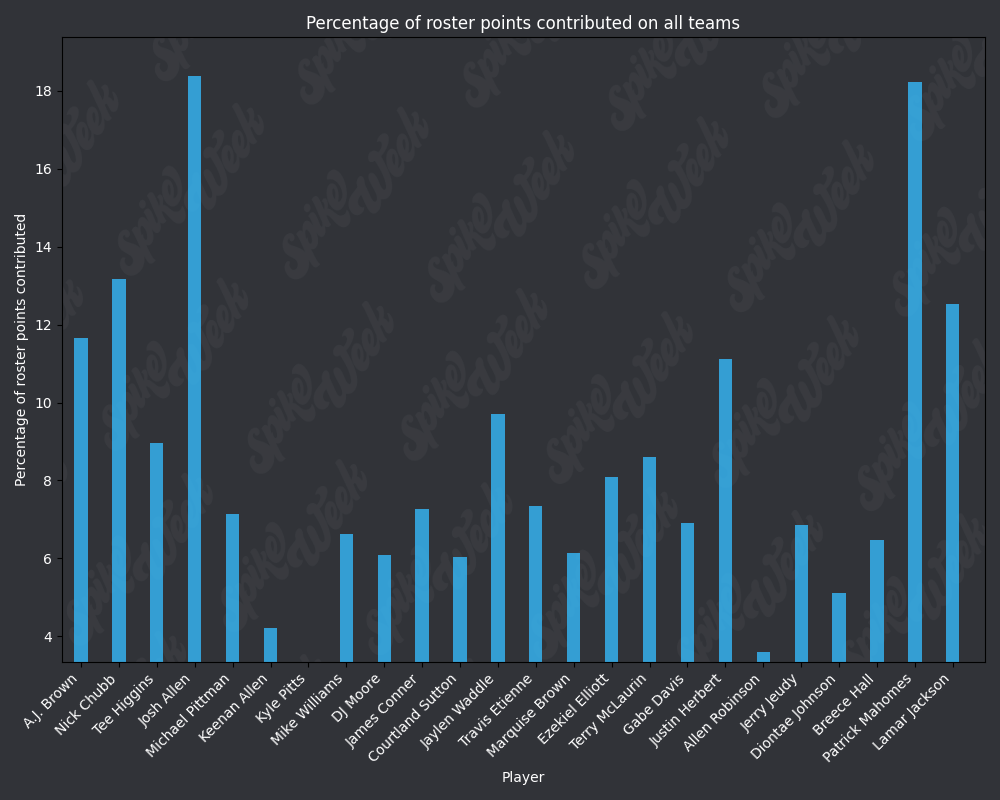
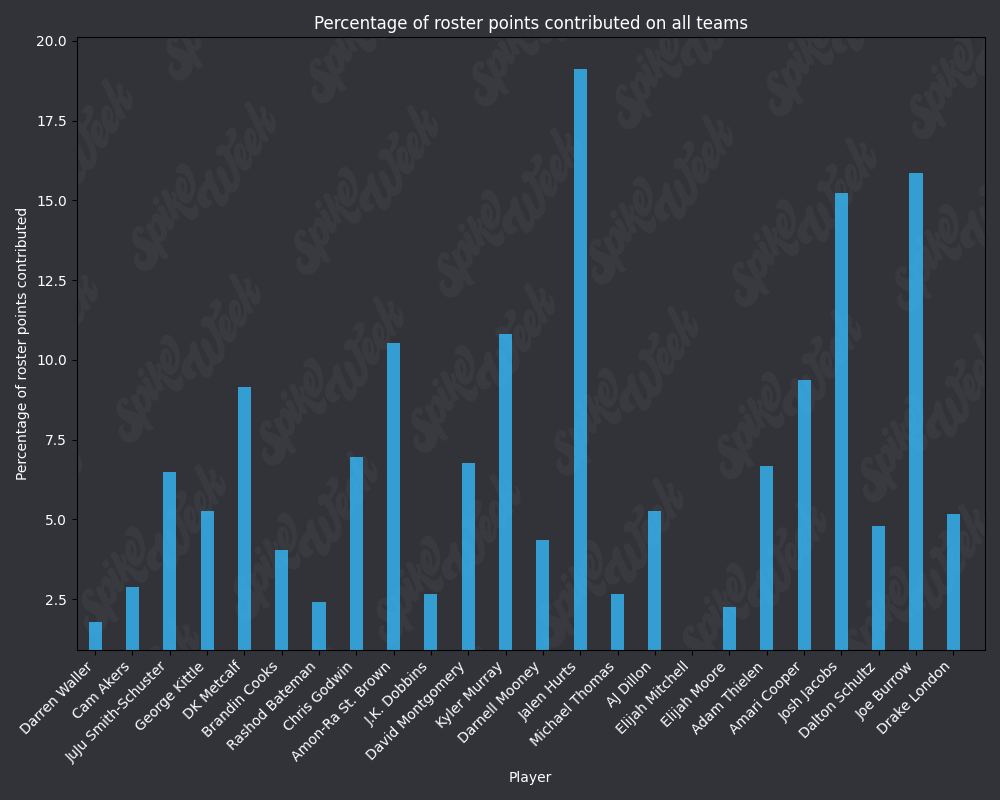
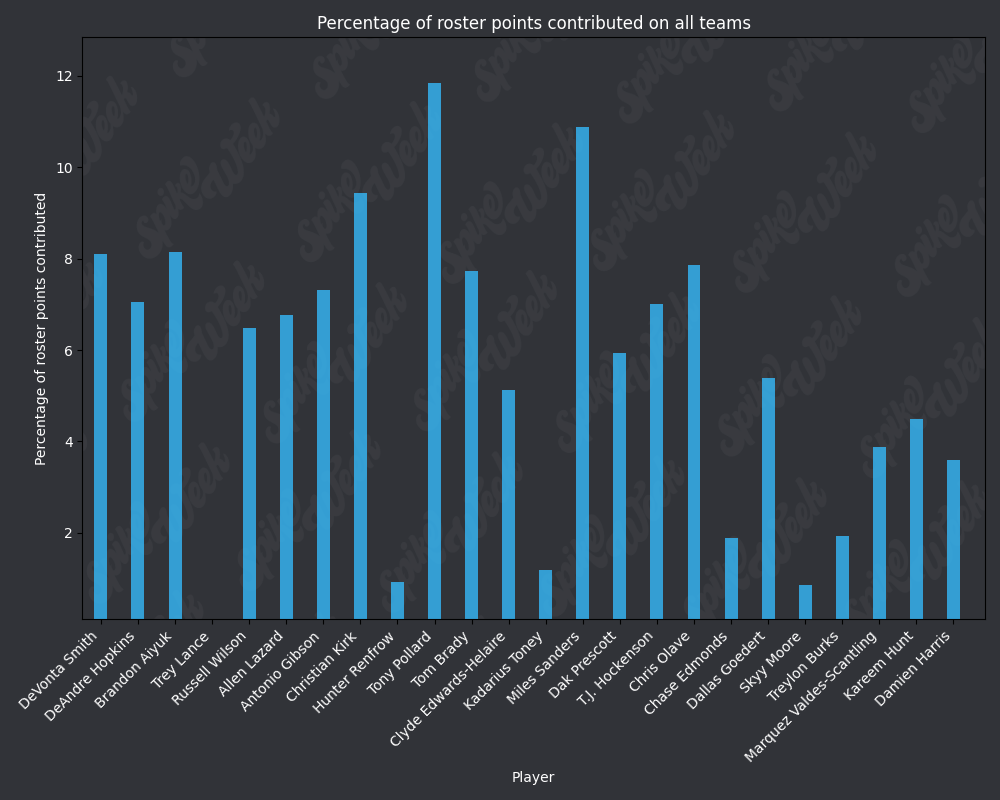
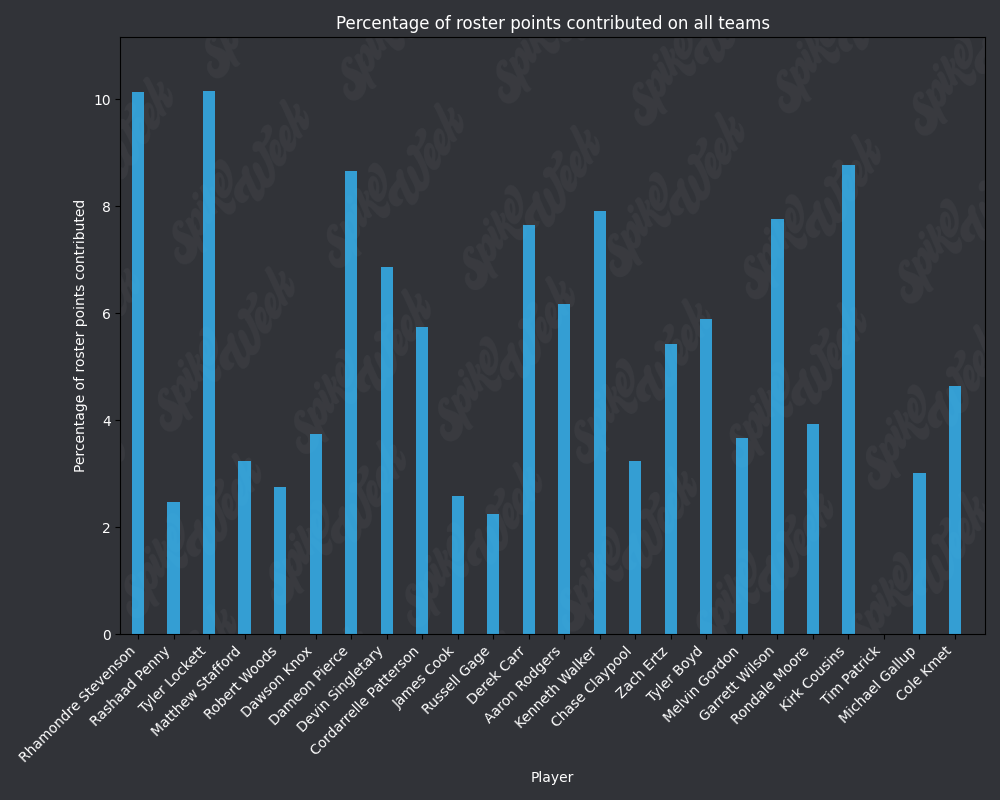
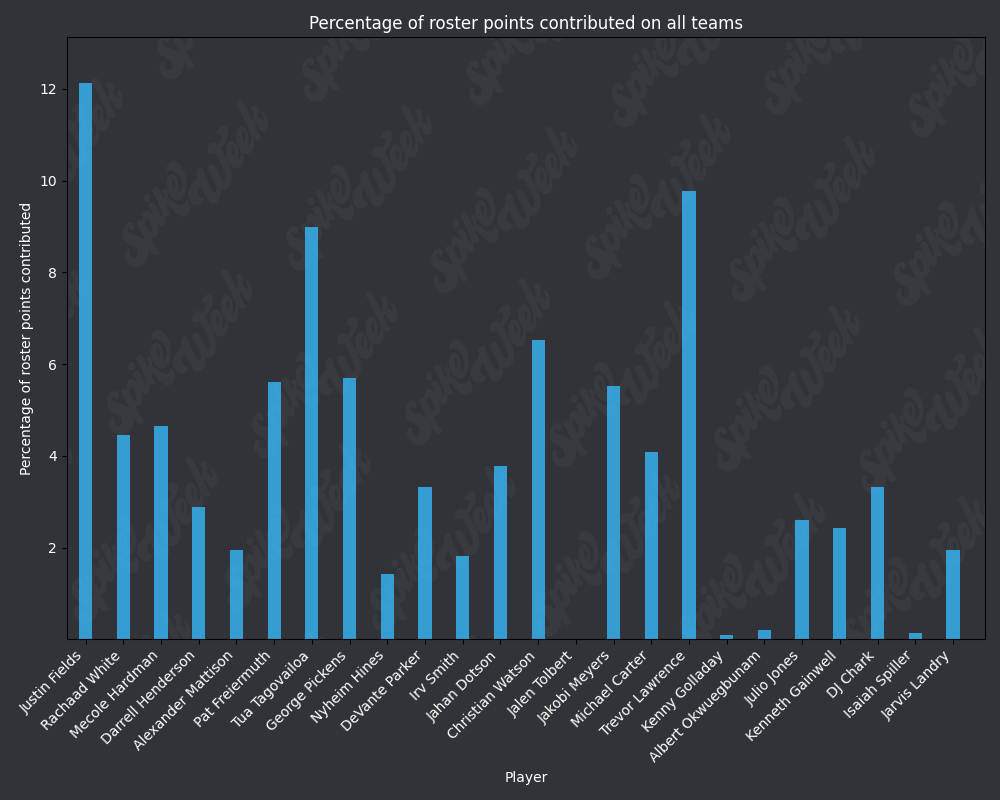
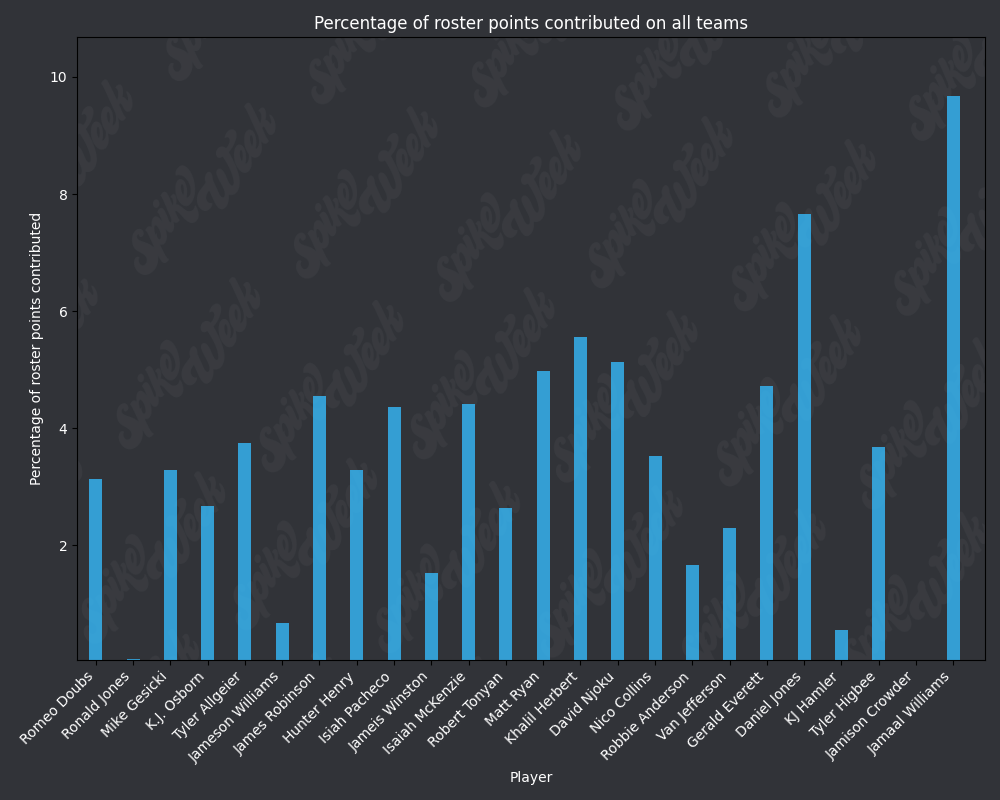
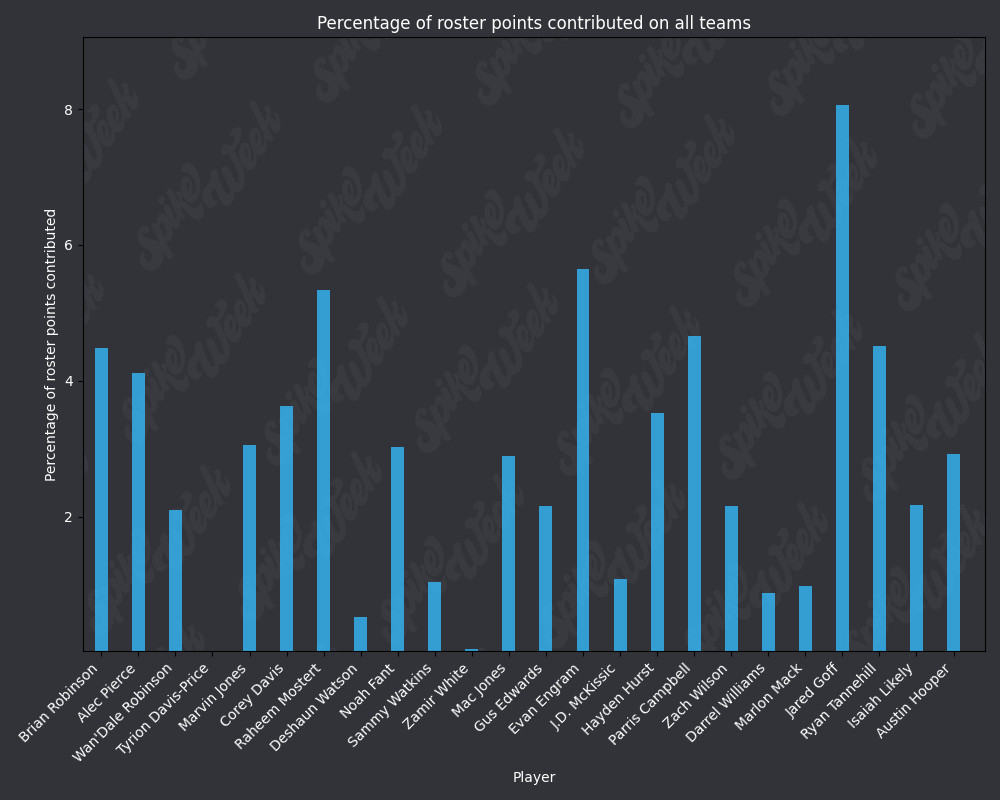
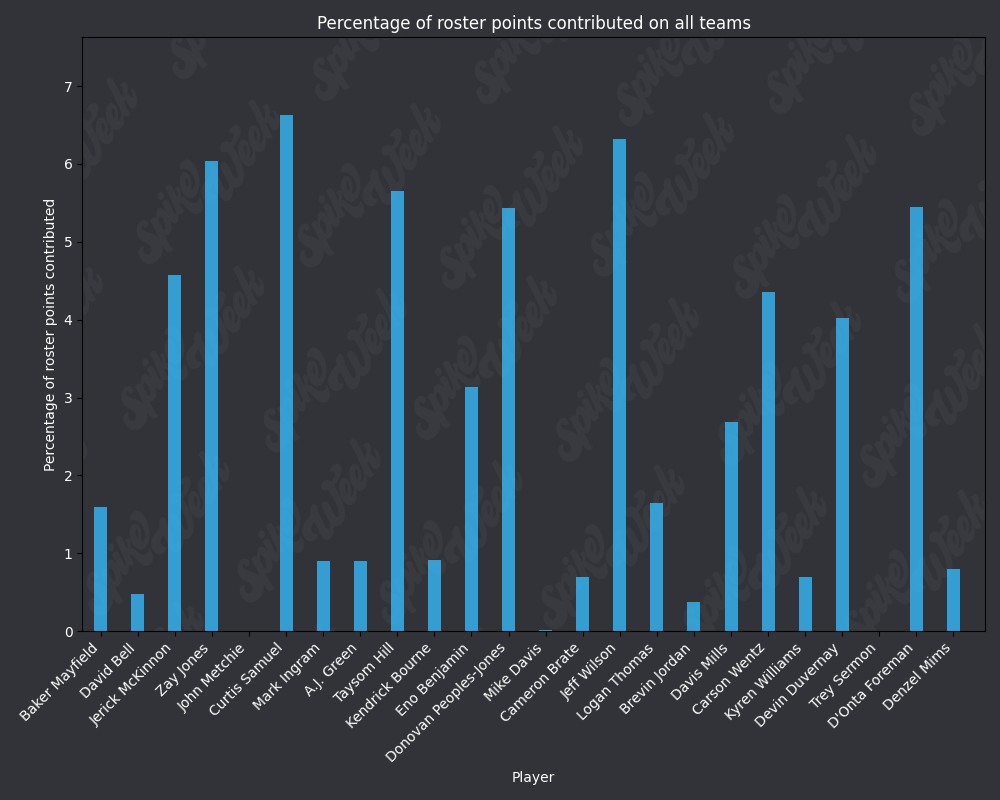
There are many potential applications for RAAR, especially when used in conjunction with APPA, PPCAT, and PPCT. There is a large amount of existing analysis in the best ball space based around advance rate/win rate. All of that analysis can be improved by utilizing these less noisy metrics that we have developed. We plan on applying these four metrics in many future projects, and we look forward to seeing how other analysts utilize them in their work.